Understanding and optimizing the performance of large-scale simulations generally relies on the availability of two data types: hardware or system software performance measurements and the context for these measurements (such as the processor or call-path involved). While the HPC community has developed a number of tools for measurement data collection, they are often geared towards specific types of analyses and maintain only limited and specialized contextual information.
Unlike the more monolithic code bases of the past, however, modern applications consist of a complex network of physics packages, numerical solvers, and support libraries. Thus a comprehensive understanding of performance behavior requires the ability to compile, analyze, and compare measurements and contexts from many independent sources.
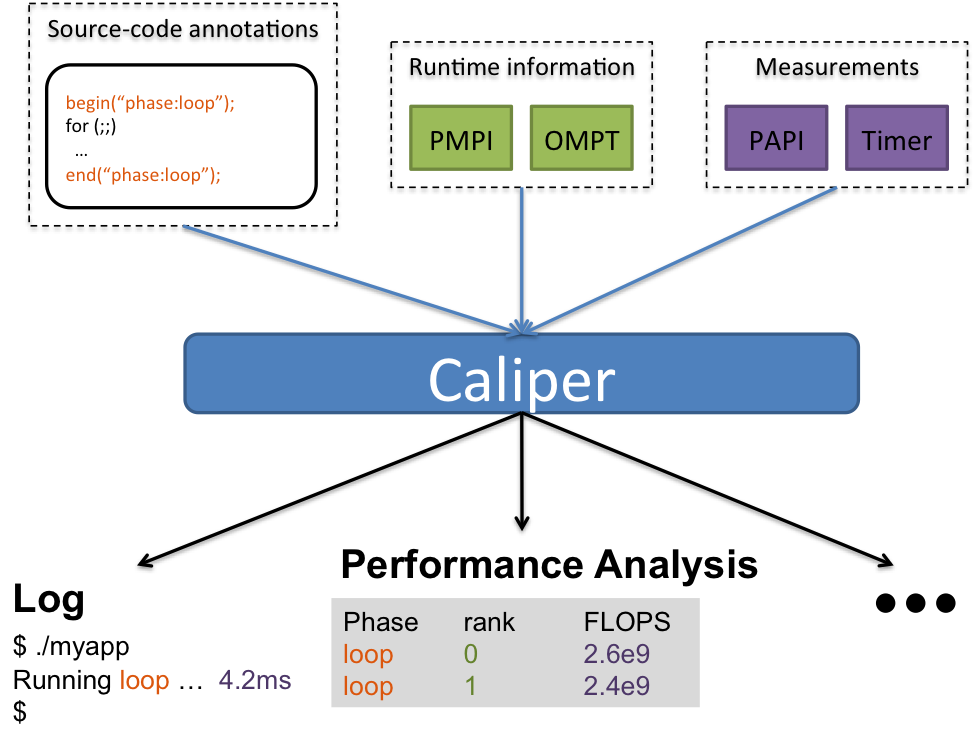
Caliper, a general-purpose application introspection system, makes that task easier by acting as the “glue” that connects various independent context annotations, measurement services, and data processing services. As both a flexible model for representing performance-related data and a transparent library for combining performance metrics and program context information, Caliper enables users to build customized performance measurement and analysis solutions.
Caliper’s key capability, composing information from different context annotations and measurement providers, is made possible by two features. First, Caliper is based on a generic attribute:value data model that allows storage of any kind of data. In contrast, classic performance analysis tools only support few, non-extensible types of automatically derived or user-provided context information.
Second, Caliper provides a process-wide, in-memory data store, which automatically combines information provided by individual annotations and attached measurement plug-in services at runtime. This allows developers to independently annotate application modules, libraries, or runtime system components, and correlate measurement data and contextual information across the software stack.
Caliper creates a single context stream of metadata and contextual snapshot records for each process. The streams are currently written to disk for offline analysis. Because of its flexible data format, importing Caliper data into external data analytics and visualization tools is a straightforward task.
We have used Caliper on various projects, including the instrumentation of several components of an LLNL radiation hydrodynamics code. Although each component is instrumented individually, Caliper allows us to look at how the components impact one other. For example, the ability to annotate the domain sizes produced by the AMR library SAMRAI and the iteration count in the hypre solver assisted application developers in studying the effects of the domain sizes on solver convergence.
Because our model handles shared context, existing instrumentation does not interfere with new instrumentation, making it easy to add new annotations as application developers see fit. This study helped to demonstrate how Caliper’s process-wide data store offers a new path towards effective and insightful performance analysis for complex HPC applications.
In 2019, Caliper made an appearance at the Virtual Institute – High Productivity Supercomputing (VI-HPS) workshop in Knoxville, Tennessee. LLNL computer scientist David Boehme conducted a 75-minute tutorial on Caliper, including hands-on exercises using the Lulesh proxy application as an example. There were around 15–20 participants, primarily HPC software developers from the University of Tennessee (Knoxville) and Oak Ridge National Laboratory, as well as the other HPC tool presenters. As a VI-HPS member organization, LLNL’s participation in the tuning workshop series helped showcase the Lab’s strong portfolio of open-source programming tools—like Caliper—among the VI-HPS partners and in the HPC community at large. Boehme's tutorial slides are available for download.