
As large language models (LLMs) and large vision-language models (LVLMs) continue to exhibit astonishing capabilities, understanding how they make predictions is an ever-evolving goal. Such foundation models play an important role in the Laboratory’s scientific workflows, which increasingly rely on artificial intelligence. But scientists need to be able to trust the models integrated into scientific applications, especially when searching for patterns in large, multimodal datasets.
Sparse autoencoders (SAEs) are widely used to interpret these types of models because they can uncover hidden structures within a model’s neural networks. SAEs can expose representations encoded with multiple concepts, then separate those representations into sparser, concept-specific features. When processing an image of a cat, for example, an SAE can discover sparse features corresponding to fur, pointed ears, paws, and whiskers.
Concept bottlenecks (CBs) offer a contrasting method, injecting an intermediate layer that forces the model’s neural network to make predictions with predefined, human-understandable concepts. Whereas an SAE discovers the cat’s features from the image’s representations, a CB predicts the concepts that describe a cat: it has fur, it has pointed ears, and so on. Because CBs are supervised, they are generally more controllable (or steerable) than unsupervised SAEs.
These techniques on their own are limited. SAEs may miss semantically meaningful concepts, while CBs are limited to the user’s fixed set of concepts. This tradeoff between interpretability and steerability persists in the literature and in practice.
Researchers from Livermore’s Center for Applied Scientific Computing (CASC) and collaborators from the University of California, San Diego (UCSD), have combined the respective strengths of SAEs and CBs—the discovery of new concepts and the control of predefined concepts—into a CB-SAE framework. Their novel approach improves both interpretability and steerability in multimodal foundation models.
CASC machine learning scientists Vivek Narayanaswamy, Shusen Liu, Wesam Sakla, and Kowshik Thopalli alongside UCSD’s Akshay Kulkarni and Tsui-Wei Weng authored “Interpretable and Steerable Concept Bottleneck Sparse Autoencoders” (preprint). The paper was accepted to the 2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), a premier venue for advances in machine-driven recognition and analysis of visual data.
“Interpretability tools are good at what they do but will not support what a user requires. This is one of the first papers that tries to merge the two viewpoints and provide a unified solution,” explains Thopalli.
Post Hoc Potential
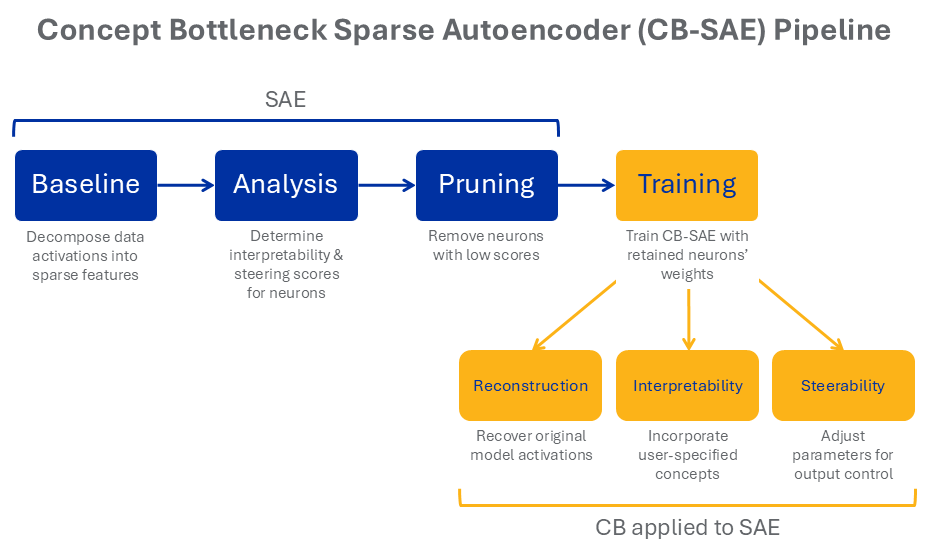
The team’s framework is designed for post hoc use, after the LLM or LVLM has been trained. At this stage of the workflow, the SAE has identified a set of neurons—computational units that produce outputs—corresponding to learned features in the model’s representations. The CB-SAE then measures how interpretable and steerable the SAE neurons are, scoring them accordingly, and prunes those that don’t make the cut.

Pruning is important because the SAE doesn’t guarantee that learned features will be semantically meaningful or useful for downstream tasks. Narayanaswamy explains, “Many times the concepts it extracts might not be complete or directly relevant to the problem you want to solve.”
The next step is to add a CB module aligned to a user-specified concept set that’s not already captured by the retained neurons, effectively replacing the pruned neurons with more useful information. For example, a general-purpose dataset could include animals, everyday objects, or scenes like those often used in image-recognition tasks. Its concept set would then break down the objects into categories (cat, dog, fish, bird), parts (tail, ears, paw, fur), appearance (striped, spotted, feathered), and other attributes. Similarly, a dataset from a scientific experiment could correspond to a concept set of physical states, conditions, or structures.
The CB-SAE pipeline’s power comes from three concurrent objectives: training the CB module to recover quality lost during pruning, to align its neurons with the user-specified concept set, and to improve the model’s overall steerability.
Downstream Design
Interpretability and steerability are difficult to achieve together in multimodal models. “We find that an SAE neuron can only provide one pure concept, and without intervention we will not get a full picture of what the SAE discovers,” states Narayanaswamy. With the CB-SAE approach, he continues, “We enforce certain concepts into the interpretability pipeline.” Instead of relying on SAE-discovered concepts alone, CB-SAE retains the highest-scoring neurons and adds user-concept-aligned CB neurons, improving measured interpretability and control of the model.
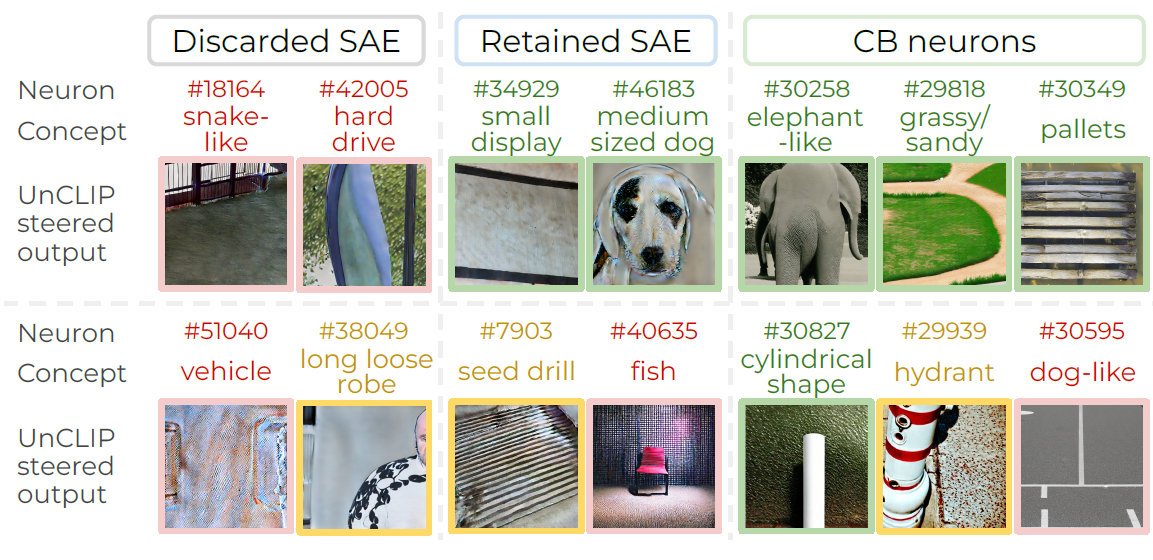
By focusing on high-quality neurons, the CB-SAE framework outperforms traditional SAEs. Furthermore, scoring the neurons is computationally inexpensive, and the CB module is a lightweight addition to the SAE. Thopalli points out, “Our technique is agnostic to the downstream method and will work for any multimodal foundation model.”
The team’s paper builds on work presented at the 2024 European Conference on Computer Vision, where Thopalli and Narayanaswamy focused on detecting failure scenarios in foundation models. More recently, the research contributes to a Laboratory Directed Research and Development Program effort led by Sakla, which aims to close gaps between multimodal foundation models and domain-specific tasks.
Other Livermore acceptances to CVPR include a workshop on trustworthy computer vision systems, co-organized by Thopalli and CASC colleague Bhavya Kailkhura.
—Holly Auten