
Disclaimer: This article is more than two years old. Developments in science and computing happen quickly, and more up-to-date resources on this topic may be available.
In this issue:
- From the Director
- Lab Impact: Applications Targeting Emerging HPC Architectures with RAJA
- Advancing the Discipline: PowerStack: A Hierarchical Approach to Power Management at Exascale
- Collaborations: Using Algebraic Multigrid Preconditioners for Scalable Simulation of Multiphase, Multicomponent Subsurface Flow
- Path to Exascale: OpenMP and Livermore: Past, Present, and Future
- Highlights
Last month, LLNL's Associate Director for Computation, Bruce Hendrickson, announced that Jeff Hittinger will be the next CASC Director. A longtime member of the CASC technical staff (he joined as a post-doc in 2000), Jeff takes on this role with well over 100 PhD-level researchers in the Center. In the announcement, Bruce stated "Jeff brings with him a wealth of experience and enthusiasm that will be well placed in this new role. In an era where computing applications and technology are undergoing rapid change, CASC will be critical to identifying and creating technologies that will shape the future of the Lab." Welcome to Jeff!
From the Director
It is an honor and privilege to be named the next Director of CASC. Thanks to my predecessors, I am assuming responsibility for an organization filled with an amazing collection of talented scientists pursuing cutting-edge research. CASC plays a very important role for the Computation Directorate and the Laboratory, bridging the needs of the Laboratory missions with the external research community in the computing sciences. The nature of scientific computing is evolving with the rapid rise of data science and with fundamental physical limitations causing changes in computer hardware.
These developments are exciting: with the new challenges they present, they also offer tremendous opportunities to invent new algorithms, to leverage learned automation, and to develop improved workflows that will more tightly couple experiment, simulation, and theory - thus accelerating scientific discovery. Within this environment, CASC must maintain its leadership in scientific computing research and ensure that its leadership is fully recognized. I look forward to working with CASC's staff, our colleagues, and our stakeholders to realize this vision.
Please look out for the next installment of the CASC Newsletter (scheduled for July), in which I will lay out my vision and plans for CASC in more detail.
Contact: Jeff Hittinger
Lab Impact | Applications Targeting Emerging HPC Architectures with RAJA
Supercomputers, like the new Sierra platform at LLNL, often employ heterogeneous processing capabilities, such as CPUs and GPUs. To reduce the challenge of programming for complex node architectures while maintaining portable code, CASC member Rich Hornung along with ASQ Division developer Jeff Keasler laid the groundwork for what would become RAJA back in 2012. RAJA is a set of C++ abstractions that allows application developers to write “single-source” application code that can be compiled to run efficiently with different on-node programming models on various hardware architectures. Developed in collaboration with application teams from LLNL's Weapon Simulation and Computing (WSC) Program, RAJA encapsulates common computational patterns and allows developers to focus on building numerical algorithms rather than the complexity of programming to a specific hardware architecture. RAJA is currently used in at least five production WSC applications and libraries and is being used or evaluated in a variety of other LLNL projects.
Using RAJA, one transforms traditional loop kernels (where most computational work in scientific applications is often performed) using an alternate loop statement, while leaving the original loop body largely untouched. Each loop kernel is parameterized with an execution policy that specifies which programming model and execution pattern will be used. LLNL applications often choose to add a wrapper layer around RAJA, which preserves application-specific semantics, allowing the application code to remain familiar to domain scientists and easing the transition to RAJA.
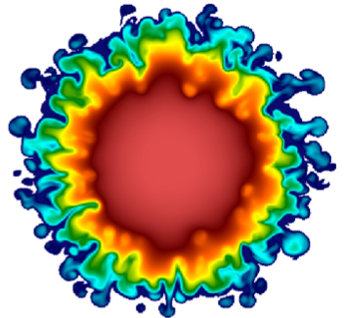
WSC applications' adoption of RAJA has been a key element in preparation for the Sierra platform. Over 90% of the computational power of Sierra resides on its NVIDIA Volta GPUs. Thus it is essential that applications run well on GPUs without sacrificing their ability to run on CPU-based clusters. The power of Sierra will enable higher resolution simulations and faster turnaround. For example, one WSC multi-physics code recently completed a high-resolution 1.5 billion zone Raleigh-Taylor mixing problem in under 4 hours on Sierra (Figure 1 at left). The same calculation would have taken several days on purely CPU-based platforms.
Supported back-ends leverage popular programming models like OpenMP, CUDA, and Intel’s Threading Building Blocks (TBB). RAJA currently supports sequential execution, SIMD vectorization, CPU multi-threading, and GPU execution via CUDA and OpenMP device offload. Future releases will support AMD’s ROCm model and OpenACC directives for GPU-offload. RAJA support for different programming model back-ends is summarized in the figure below.
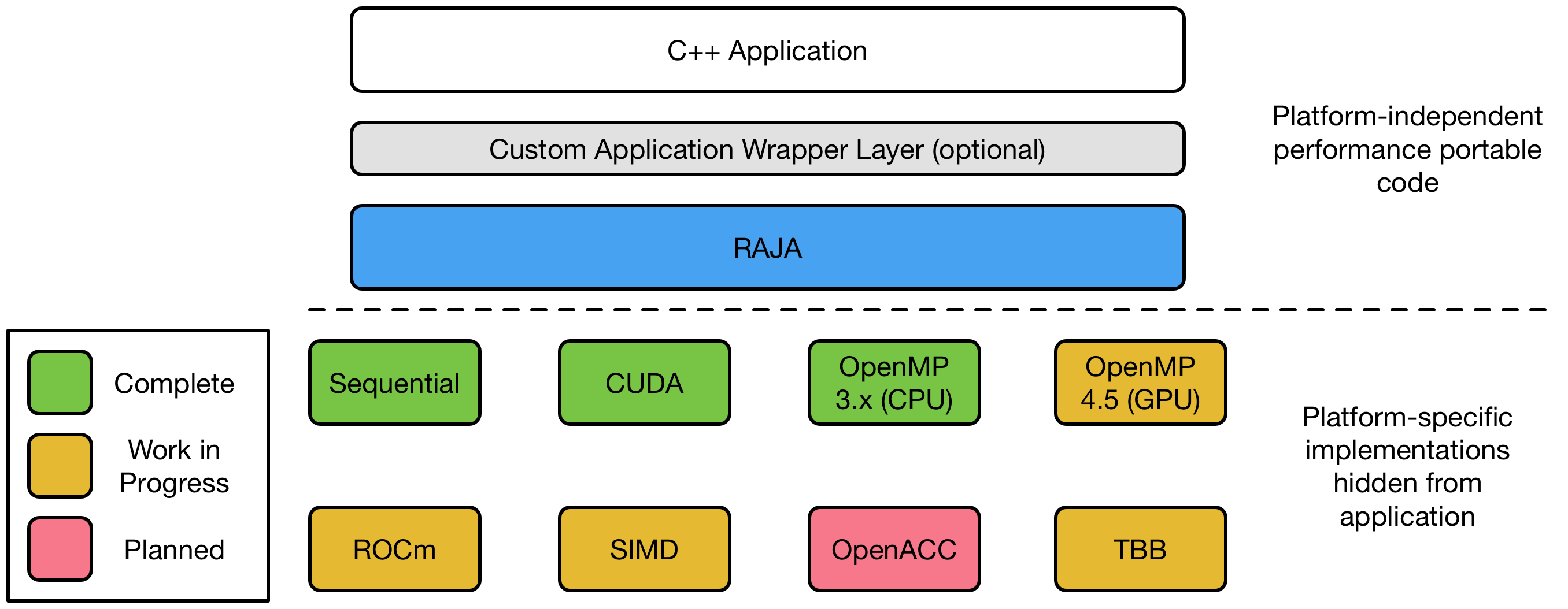
RAJA is an open-source project on GitHub and is supported by ASC and the DOE Exascale Computing Project (ECP). RAJA is also a key part of LLNL co-design efforts with vendors. Working with the RAJA team, vendors can rapidly move RAJA-based applications to new architectures by providing or modifying a back-end implementation. The RAJA Performance Test Suite was recently released to help streamline this process and ensure that performance issues related to the introduction of RAJA abstractions are caught early. RAJA-based benchmarks will be used in the CORAL-2 machine procurement, scheduled to deliver systems at ORNL and LLNL in 2021-22, ensuring ongoing vendor support for this project.
The RAJA team includes CASC researchers David Beckingsale, Rich Hornung, Olga Pearce, and Tom Scogland; Livermore Computing and AAPS team members Holger Jones and David Poliakoff; and ASQ/WSC collaborators Jason Burmark, Adam Kunen, and Arturo Vargas. External collaborators include Millersville University, University of Bristol, Harvey Mudd College, Intel, IBM, and AMD.
Contacts: Rich Hornung, David Beckingsale
Advancing the Discipline | PowerStack: A Hierarchical Approach to Power Management at Exascale
As we venture towards the exascale era, resources such as power and energy are becoming limited and expensive. Efficiently utilizing procured system power while optimizing the performance of scientific applications under power constraints is a key thrust area in DOE’s Exascale Computing Project (ECP). Although hardware advances will contribute a certain amount towards achieving high energy efficiency, they will not be sufficient, creating a need for a sophisticated system software approach.
Power management in software is challenging due to the dynamic phase behavior of applications, processor manufacturing variability, and the increasing heterogeneity of node-level components. While several scattered research efforts exist, a majority of these efforts are site-specific, require substantial programmer effort, and often result in suboptimal application performance and system throughput. Additionally, these approaches are not production-ready and are not designed to cooperate in an integrated manner. A holistic, generalizable and extensible approach is still missing in the HPC community.
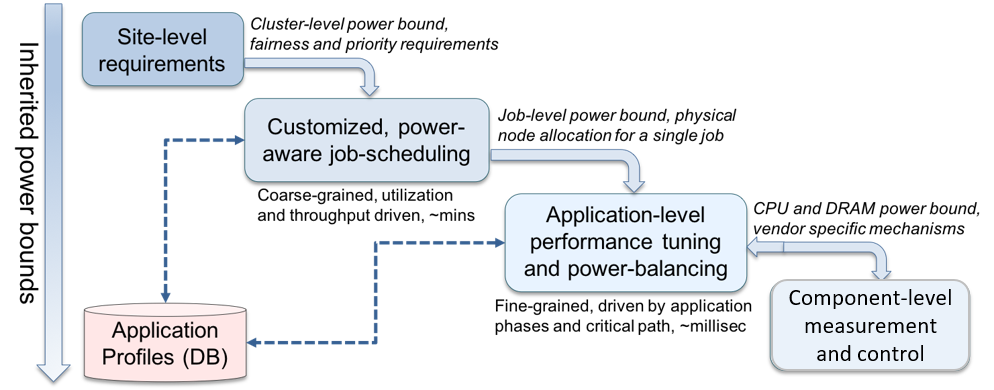
As part of the ECP Argo and the ECP Power Steering projects, we are designing a scalable and extensible framework for power management, which we refer to as the PowerStack. PowerStack will explore hierarchical interfaces at three specific levels: batch job schedulers, job-level runtime systems, and node-level managers. Each level will provide options for adaptive management depending on the requirements of the supercomputing site under consideration. Site-specific requirements such as cluster-level power bounds, electricity provider constraints, or user fairness will be translated as inputs to the job scheduler. The job scheduler will choose power-aware scheduling plugins to ensure site-level compliance, with the primary responsibility of serving multiple users and diverse workloads by allocating nodes and job-level power bounds. Such allocations of physical nodes and job-level power bounds will serve as inputs to a fine-grained, job-level runtime system that manages specific application ranks and understands critical paths; in-turn relying on node-level measurement and control mechanisms. Continuous monitoring and analysis of application behavior may be required for decision-making. Figure 3 below presents an overview of the envisioned PowerStack.
Active development is underway for all three levels of the PowerStack. At the job scheduler level, we have extended Flux to address the issue of manufacturing variability under power constraints. Manufacturing variability is a characteristic of the underlying hardware, where processors with the same microarchitecture that are expected to be homogenous can exhibit significant differences in CPU performance, making applications sensitive to node placement and impacting their execution times drastically. With our variation-aware policy in Flux, we can reduce rank-to-rank performance variation on clusters such as Quartz and Cab (large Linux clusters at LLNL) by 2.3x.
As part of the DOE/MEXT initiative, we collaborated with Kyushu University and The University of Tokyo to develop a power-aware version of SLURM that has been evaluated at scale on the 965-node HA8K supercomputer. This is now being extended further to support ECP policies and to interact hierarchically with a job-level runtime system. We are currently evaluating policies at the job scheduler level to understand site-specific requirements.
We are working closely with Intel to develop advanced plugins for an open-source job-level runtime system, called Intel GEOPM. Using configuration selection and application annotation through Caliper, we can provide GEOPM with semantic information that allows for fine-grained control of power across application ranks, as well as distribution of power between processors and memory. For the node-level, we have developed msr-safe and libmsr for power measurement and control for Intel architectures. We are also interacting with IBM in order to develop vendor-agnostic techniques. Integration efforts to develop interfaces for hierarchical management and flow across these three management levels are ongoing.
The project PI, Tapasya Patki, was recently interviewed for a podcast as part of an ongoing series produced by the ECP.
The PowerStack team includes CASC personnel Barry Rountree, Aniruddha Marathe, Tapasya Patki, and Lawrence Scholar Stephanie Labasan. The team works closely with LC ProTools (Kathleen Shoga and Marty McFadden) and LLNL's Flux team (Dong Ahn, Jim Garlick, Mark Grondona, Tom Scogland, Stephen Herbein, Al Chu, Ned Bass, Becky Springmeyer). External collaborators include Intel (Jonathan Eastep's GEOPM group), Argonne National Laboratory (Pete Beckman's Argo group), Technical University Munich (Martin Schulz's group), University of Tokyo (Masaaki Kondo's group), and University of Arizona (David Lowenthal's group).
Contact: Tapasya Patki
Collaborations | Using Algebraic Multigrid Preconditioners for Scalable Simulation of Multiphase, Multicomponent Subsurface Flow
Accurate modeling and simulation of geomechanical processes is critical to the safety and reliability of our subsurface energy sources. Applications in geosciences typically require coupling multiple physical phenomena at different scales, over large physical domains. As a result, simulations are increasingly complex, requiring expertise from multiple disciplines. Over the past few years, LLNL has partnered with ExxonMobil to address some of the challenges in their reservoir modeling and simulation capabilities. This partnership has leveraged CASC’s expertise in HPC, data mining, uncertainty quantification, model reduction and solvers. It is well known in the reservoir modeling community that efficient linear solver technology based on robust and scalable multilevel methods is critical to enable large-scale simulation of applications from real fields. To address this need, a collaboration was formed between LLNL’s hypre team and the computational modeling team from ExxonMobil, as part of the larger partnership.
To develop a robust solver technology for multiphase flow applications, the initial approach taken was to explore the state-of-the-art in the community to identify opportunities to utilize and build upon hypre’s scalable multigrid framework. This effort led to the development of the multigrid reduction (MGR) solver strategy in hypre. Multigrid reduction is a multigrid-based iterative solution technique derived from approximating an underlying direct reduction approach. It has been shown to be effective for Poisson-like equations and anisotropic problems and has recently been used for non-intrusive parallel time integration.
The MGR framework allows many of the two-stage preconditioners currently used in reservoir simulation codes to be formulated as a standard multigrid approach (see figure 4 below). This enables a comparison of different two-stage solver strategies in a common framework and provides insights into the advantages and disadvantages of different algebraic characteristics of the solvers. Consequently, it provides an opportunity to develop robust solver strategies for linear systems of equations for applications involving coupled variables, and not limited to reservoir modeling.

The MGR solver is now available in the latest release of hypre. The solver’s performance has been demonstrated on problems from multiple applications, including models from real fields provided by our ExxonMobil collaborators. One challenge to the development of robust solver techniques for reservoir models is that the addition of new physics can impact solver behavior. For example, it is common to include well models in the reservoir model to represent injection and production processes in the simulation. However, well information is typically included into the model in the form of constraint equations that are purely algebraic. The lack of a differential formulation for the well equations leads to a coupled linear system that is challenging for standard multigrid solvers. Work is ongoing to address this challenge using the MGR framework to identify contributions from well components and develop effective solver strategies.

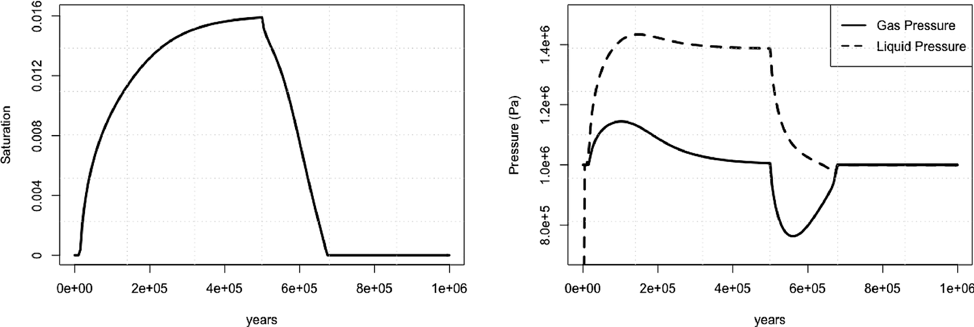
Additional opportunities for MGR include applications in carbon sequestration and contaminant remediation. This is demonstrated in recent work for two-phase flow in porous media with phase transitions, shown in Figure 5 above. Furthermore, the MGR strategy forms the basis for the development of algebraic multigrid preconditioners for the LDRD funded project on scalable simulation of reservoir geomechanics and multiphase flow. One key difference here is that the models include mechanics, which describe displacements and structural deformation of solid subsurface materials.
ExxonMobil Collaborators include Ilya Mishev and Jizhou Li.
Contacts: Daniel Osei-Kuffuor, Lu Wang, Rob Falgout
The Path to Exascale | OpenMP and Livermore: Past, Present, and Future

LLNL has driven the OpenMP specification forward throughout its twenty year history: LLNL staff member Mary Zosel helped lead the very first planning committee; and today Bronis de Supinski played a lead role in defining the memory model and has been serving as the language committee chair since version 3.1. CASC researcher Tom Scogland is now helping drive the offload model and heterogeneous memory support since Version 4 of the OpenMP standard. The rise of heterogeneous computing, and the arrival of Sierra and the Sierra Center of Excellence driving LLNL in particular, have inspired a wide range of research into improvements to allow OpenMP to better cope with these in-node sometimes-distributed memory machines.
In particular LLNL has driven the design and acceptance of extensions to support the compliant use of unified memory with the requires directive, deep copy for complex data structures with declare mapper (and more complex structures to come), the inclusion of a portable tools interface (OMPT) for profiling and introspection and shaped a variety of improvements in the memory model and general ergonomics of the programming model. All of these were motivated by early experiences and can be seen in the public comment draft of OpenMP 5.0 released as TR6.
Since TR6 there have been major advances in base-language support, especially for C++ going from C++03 to C++17, and support for C++ abstractions that make heavy use of lambdas and templates such as Kokkos and RAJA (see RAJA article earlier in this newsletter). Early experiences and research into using and extending these models with OpenMP 4.x have driven an ongoing co-design effort between LLNL and IBM culminating in several improvements in support, including mapping lambda captures and support for conditional compilation based on the device being compiled for. The tools effort is also driving forward working on support for a portable debugger (OMPD) interface, with the hopes of providing OpenMP contextual information across implementations.
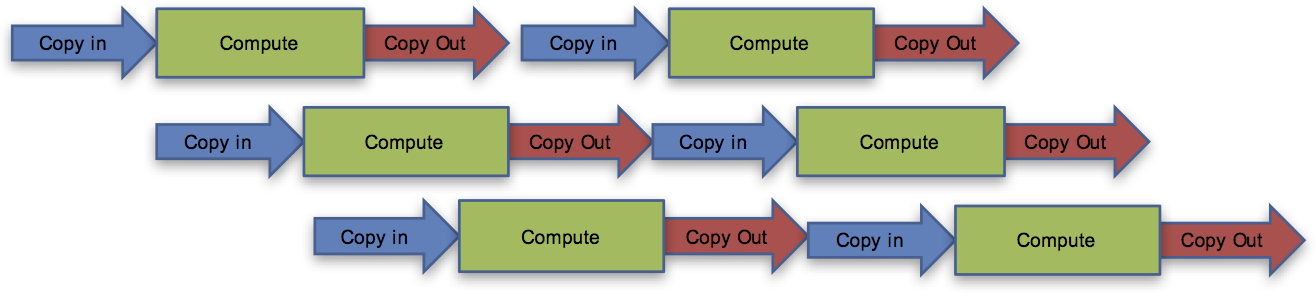
As part of our forward-looking research, we're currently investigating ways to help automatically pipeline data transfers and computation (see figure 6), cross-language support for closures, cross-device worksharing, and supporting arbitrarily complex deep copy among others through our own work as well as collaborations through the Exascale Computing Project's SOLLVE effort.
Contact: Tom Scogland
CASC Highlights
New Hires (Since January 1, 2018)
- Tristan Vanderbruggen
- Delyan Kalchev
Awards
- Panayot Vassilevski was named a Fellow of the Society for Industrial and Applied Mathematics, the world's largest professional association devoted to applied mathematics.
Looking back... 20+ years of ROSE development
ROSE is a 25-year-old effort developed at LLNL since Dan Quinlan moved into the CASC almost 20 years ago. ROSE supports the development of full compilers and compiler-based tools through automated analysis and transformations on both source code and binary executables.
How it started: the early years (mid 1990s – 2004)

Initially a single-developer effort, ROSE started as a specialized tool to support optimization of high-level C++ abstractions defined within both the A++/P++ array class and the Overture library. A++/P++ was developed to support thesis work on Adaptive Mesh Refinement (AMR) codes with a common serial (A++) and parallel (P++) array interface. Overture was a Los Alamos based project that used A++/P++ for overset grid computations that moved to LLNL in 1998 when David Brown, Bill Henshaw, and Dan Quinlan moved to CASC. The increased interest and funding opportunities for ROSE soon demanded support for the entirety of C and C++. Early work on ROSE within CASC was funded by ASC and focused on language support for ASC applications through source-to-source transformations initially aimed at increasing node-level performance.
A timeline of modern ROSE development
A series of additional requests from sponsors and customers led to an expanding scope for ROSE over the years. Some timeline highlights from the past decade include:
- 2004 - Released as open source under the BSD license. Fortran support added. Argonne National Lab adopts for their Automatic Differentiation for C (ADiC) compiler.
- 2008 - Project moves to GitHub. OpenMP support added. Binary executable analysis support added.
- 2009 - ROSE wins an R&D 100 award
- 2010 - OpenCL and CUDA support added. The Software Engineering Institute becomes a significant external user and collaborator, helping introduce robust continuous integration.
- 2011 - Ability to use LLVM/Clang frontend, and ability to generate LLVM IR from the ROSE abstract syntax tree (AST) initiated at Rice University
- 2012 - ROSE begins a long continuous winning streak at the software verification challenge, Rigorous Examinations of Reactive Systems, RERS)
- 2013 - First GPU work started using the Mint compiler (UCSD) and an OpenACC implementation (University of Delaware). Commercial version of EDG Front end purchased, allowing ROSE to be used outside of strictly research settings.
- 2014 - Java language support through DoD support
- 2015 - ASC support reestablished for development of source-to-source tools accelerating the refactoring of LLNL codes preparing for Sierra
- 2016 - Work started with DoD ESTCP program
- 2017 - Joins the DOE Exascale Computing Project to develop Autopar and CodeThorn supporting automated parallelization and verification of correctness in HPC applications
Over this time, ROSE has grown into a social enterprise of sorts, with about a hundred students and many staff members contributing, and long-term support from both internal and external customers. It has become a vehicle for the team to work with a larger group of people and institutions than initially imagined, notably in areas of performance optimizations, performance analysis, software engineering, software assurance, and cyber security. The customer base has continued to expand over the years, and now ROSE has over a dozen people and over twenty different projects contributing to the work which addresses development of new tools, addition of new languages, and expansions of ROSE capabilities.
Contact: Dan Quinlan
CASC Newsletter Sign-up
Was this newsletter link passed along to you? Or did you happen to find it on social media? Sign up to be notified of future newsletters, which we release approximately every 3 months.
LLNL-WEB-749771