
Disclaimer: This article is more than two years old. Developments in science and computing happen quickly, and more up-to-date resources on this topic may be available.
In This Issue:
- From the Director: CASC at SC18
- Lab Impact: Debris and Shrapnel Modeling for the National Ignition Facility (NIF)
- Advancing the Discipline: Enabling Scalable Simulation-Based Optimal Control and Design of Complex Engineering Systems
- Collaborations: Living on the Edge of Magnetic Fusion Simulation
- Path to Exascale: XPlacer: Data Placement Engine for Heterogeneous Supercomputers
- Looking Back: LLNL's Legacy in the SC Conference
- Highlights
From the Director
In November, LLNL and CASC wrapped up another strong showing at the SC18 Conference which was held in Dallas, TX. At this premier international conference on high performance computing (HPC), LLNL was well-represented in the highly selective technical program with participation in four keynote or DOE Booth talks, eight technical papers, eight technical posters, six tutorials, ten Birds-of-a-Feather symposia, two panels, and twelve workshops. In addition, LLNL was active in the planning of SC18, providing 27 conference committee members. Todd Gamblin (shown above presenting Best Paper awards) also worked with Chair Torsten Hoefler of ETH-Zurich to revamp the submissions process this year.
The sheer breadth of involvement that LLNL continues to have in this conference demonstrates our leadership role in HPC, and CASC researchers participated in a large number of these LLNL contributions. If you attended the conference technical sessions, workshops, or tutorials, there is a good chance you learned about the research and software of CASC!
However, research contributions as represented by our showing at SC18 are just a part of what CASC does. Like LLNL as a whole, CASC is also mission-focused, delivering top-notch solutions to LLNL programs and sponsors who bring to us some of the most challenging problems in science and national security. It is as honor and a privilege to lead an organization that brings such expertise, ingenuity, and commitment to bear on problems of national importance. I hope you enjoy reading about some of our most recent work below and encourage you to take a look at some of our previous newsletter editions while you are here.
Contact: Jeff Hittinger
Lab Impact | Debris and Shrapnel Modeling for the National Ignition Facility (NIF)
A typical experiment at the National Ignition Facility focuses the 3ω (351 nm) laser light onto target components to produce the desired thermodynamic, x-ray, and hydrodynamic conditions. The laser pulses are about 2–30 ns in duration and, after the data is collected—during or within 10s of ns of the end of the laser pulse—the shot is over… for the experimentalists. For the facility, the x-ray emissions and fast-moving target remnants may still pose a threat.

The laser optics are protected by 3-mm thick borosilicate glass Disposable Debris Shields (DDS), which are a few hundred dollars each and can be swapped automatically in a cassette. All upstream optics are orders of magnitude more expensive with few spares and significant downtime for replacement. Damage to more than a few DDS or any of the upstream optics would incur a significant expense and schedule disruption. Diagnostic filtration must be balanced between adequate transmission and physical protection of the instrument. The expense of replacing a damaged diagnostic instrument is significant and largely due to the calibration required—which, for an x-ray framing camera, may take a month or more at beamlines with limited availability.

For both optics and diagnostics, predictions of the nature, trajectory, and speed of target debris and the potential consequences are needed to determine appropriate risk management strategies that balance facility and user, including programmatic, interests. The NIF Debris & Shrapnel Working Group, led by CASC researcher Nathan Masters, assesses all targets and diagnostics fielded on NIF for potential threats to optics and diagnostics posed by the experiments and works with the experimental teams and facility to minimize the risk. In order to “protect the facility and facilitate the science” D&S uses a variety of tools: ARES for laser-target interactions and target response out to about 5 µs (if possible), including identification of solid and molten shrapnel; ALE3D and LS-DYNA for structural responses to distributed debris wind or x-ray ablative loads and discrete impacts; and analytic and empirical models. Many target and diagnostic configurations have been fielded previously, so detailed assessments are reserved for those that are significantly different.
Some of the most challenging assessments to date have been associated with the High Energy Density campaigns: Material Strength Rayleigh-Taylor MatStrRT, TARDIS (TArget x-Ray Diffraction In-Situ), and Equation of State (EOS)—which evaluate the material properties: strength, crystallographic structure, and equation of state of various materials of programmatic interest at extreme pressures and temperatures. The Material Strength Rayleigh-Taylor campaign uses a hohlraum to drive Rayleigh-Taylor instabilities in a material sample. The growth of the instabilities is radiographed using a backlighter foil and a passive diagnostic. A shielding aperture, in the form of an 11 mm x 17 mm x 1 mm gold plate, is attached to the side of the hohlraum to block hohlraum emissions that would otherwise drown the signal of interest (see Figure 1).

Modeling in ARES of the target and shield identified designs that would not pose a significant risk to optics (see Figure 2) although shrapnel from the shield and physics package were predicted to be driven towards the primary diagnostic at velocities between several hundred m/s and 8 km/s (Figure 3 shows shrapnel impacts on the diagnostic nose cap). D&S designed a filtration stack consisting of spaced layers of boron carbide and polycarbonate to minimize the risk that the image plates would be damaged or contaminated by sample materials (see Figure 4, left). This configuration has been fielded five times to date and performed well (Figure 4, right).

Current members of the group are Andrew Thurber and Rosita Cheung (both from Engineering) and Michelle Oliveira (NIF). A number of current and former CASC personnel have contributed over the years including Aaron Fisher, Brian Gunney, Bob Anderson, Noah Elliott, and Alice Koniges.
Contact: Nathan Masters
Advancing the Discipline | Enabling Scalable Simulation-Based Optimal Control and Design of Complex Engineering Systems
In the design, control, and/or operation of engineering systems, we seek to optimize some objective while satisfying a set of operating conditions and/or engineering constraints. Such problems are naturally expressed as mathematical optimization problems. For example, additive manufacturing (AM) provides unique capabilities to build complex structures, and topology optimization for AM aims to minimize weight while maximizing stiffness, under physical (elastic deformation laws) and manufacturing process constraints. Similarly, electricity dispatch on power grids is performed by minimizing the generation costs while satisfying the laws of electrical flow in the grid and various other generation constraints. In order to enforce physical constraints efficiently at the desired high-resolutions and/or large scale, simulations based on state-of-the-art partial differential equation (PDE) or differential algebraic equation (DAE) solvers need to be embedded in the optimization process. The resulting simulation-based optimization paradigm can reach extreme sizes and complexity (e.g., billions of optimization parameters) and thus necessitates the use of high performance computing (HPC).
Scalable algorithms, where the number of iterations in an optimization search do not increase (or increase weakly) with the number of optimization parameters, can be generally obtained only by using second-order derivative (i.e., Newton-like methods). However, using exact second-order sensitivities is problematic in simulation-based optimization, since few simulation codes provide derivative information and/or the second-order derivatives are computationally intractable. Quasi-Newton algorithms are a pragmatic and convenient alternative, since they internally build approximations of the second-order derivatives and even achieve Newton-like performance. In many cases, quasi-Newton methods can be improved. The work from [2] incorporates the second-order derivatives that are available for a subset of the constraints to improve the quality of the Hessian approximation. In addition, for constraints specific to PDEs, infinite-dimensional quasi-Newton methods that work directly with underlying Hilbert functional space show a huge improvement in iteration count and robustness over traditional “Euclidean” methods [3].

The HiOp solver developed in the last two years in The CASC software HiOp incorporates the above-mentioned algorithms. The computational decomposition in HiOp is achieved by using a combination of specialized block Gauss elimination and explicit formulas for the inverse of the quasi-Newton limited-memory secant approximations [1] for the quasi-Newton linear systems. This technique requires only parallel dense matrix-vector multiplications and solving small dense linear systems using only intra-node computations. Good theoretical speedup occurs whenever the underlying simulator can expose data parallelism to HiOp [1], as it is the case of PDE-constrained optimization depicted in Figure 5. The reliance on dense linear algebra makes it likely that the accelerators of the emerging exascale HPC platforms can be efficiently used by HiOp. Such developments are currently under the investigation for GPUs and FGPAs.

HiOp is being currently used by the Livermore Design Optimization (LIDO) framework for topology optimization and material design optimization. LIDO uses the scalable MFEM solver for solving the elasticity PDEs governing these optimization problems. With HiOp as the optimization library, LIDO is capable of reaching designs of unprecedented resolutions such as the quadmotor drone design shown in Figure 6. At the highest resolution, the topology optimization problem comprised of 880 million optimization parameters and was solved on LC’s Quartz system using 9,216 cores.
[1] C. G. Petra, A memory-distributed quasi-Newton solver for nonlinear programming problems with a small number of general constraints, Journal of Parallel and Distributed Computing, in print, 2018.
[2] C. G. Petra, N. Chiang, M. Anitescu, A structured quasi-Newton algorithm for optimizing with incomplete Hessian information, accepted to SIAM J. of Optimization, 2018.
[3] C. G. Petra, M. Salazar De Troya, N. Petra, Y. Choi, G. Oxberry, D. Tortorelli, A secant quasi-Newton interior-point method for optimization in Hilbert space, submitted to SIAM J. of Scientific Computing, 2018.
Contact: Cosmin Petra
Collaborations | Living on the Edge of Magnetic Fusion Simulation
For more than a decade, CASC researchers have been collaborating with the LLNL Fusion Energy Program (FEP) in the development of advanced numerical methodologies for magnetic fusion energy (MFE) applications. The LLNL FEP is a recognized world leader in MFE research, especially in research focused on the “edge” region of tokamak fusion reactors, where the understanding of plasma behavior is critical for reactor design and performance optimization. As part of a project jointly funded by the DOE Offices of Fusion Energy Sciences (FES) and Advanced Scientific Computing Research (ASCR), CASC and FEP researchers are developing an edge plasma simulation code named COGENT that employs new computational techniques.
First among the simulation challenges is the fact that edge plasmas cannot be modeled well as fluids. The use of approximate gyrokinetic models provides some simplification of an otherwise fully kinetic model, but one is still faced with the need to solve a system of partial differential equations in five independent variables plus time, in addition to some form of Maxwell’s equations. Other numerical challenges result from the strong anisotropy associated with plasma flow along magnetic field lines, geometric constraints imposed by the sheared magnetic geometry comprised of open and closed field lines, and simultaneous treatment of multiple time and spatial scales corresponding to plasma (micro-scale) turbulence and (macro-scale) transport.
Although particle-based approaches provide a natural choice for kinetic simulations, the associated noise and accuracy uncertainties pose a significant concern. As an alternative, COGENT employs a continuum (Eulerian) approach in which the gyrokinetic system is discretized and solved on a phase space grid. The computational costs associated with the use of grids in four (assuming axisymmetric configuration space geometry) or five spatial dimensions are partially mitigated via fourth-order discretization techniques, which reduce the number of grid cells needed to achieve a specific accuracy relative to lower-order methods. The edge geometry is described using a multiblock approach in which subregions are mapped to locally rectangular grids that are further domain decomposed for parallelization. Alignment of the block mappings with the magnetic field and a specially-developed discretization of the phase space velocities isolates the strong flow along field lines for improved discretization accuracy. Multiple time scales are treated using an Additive Runge-Kutta (ARK) time integration framework in which the CASC-developed hypre BoomerAMG algebraic multigrid solver is employed in preconditioners for the Newton-Krylov nonlinear solves required in the implicit ARK stages.
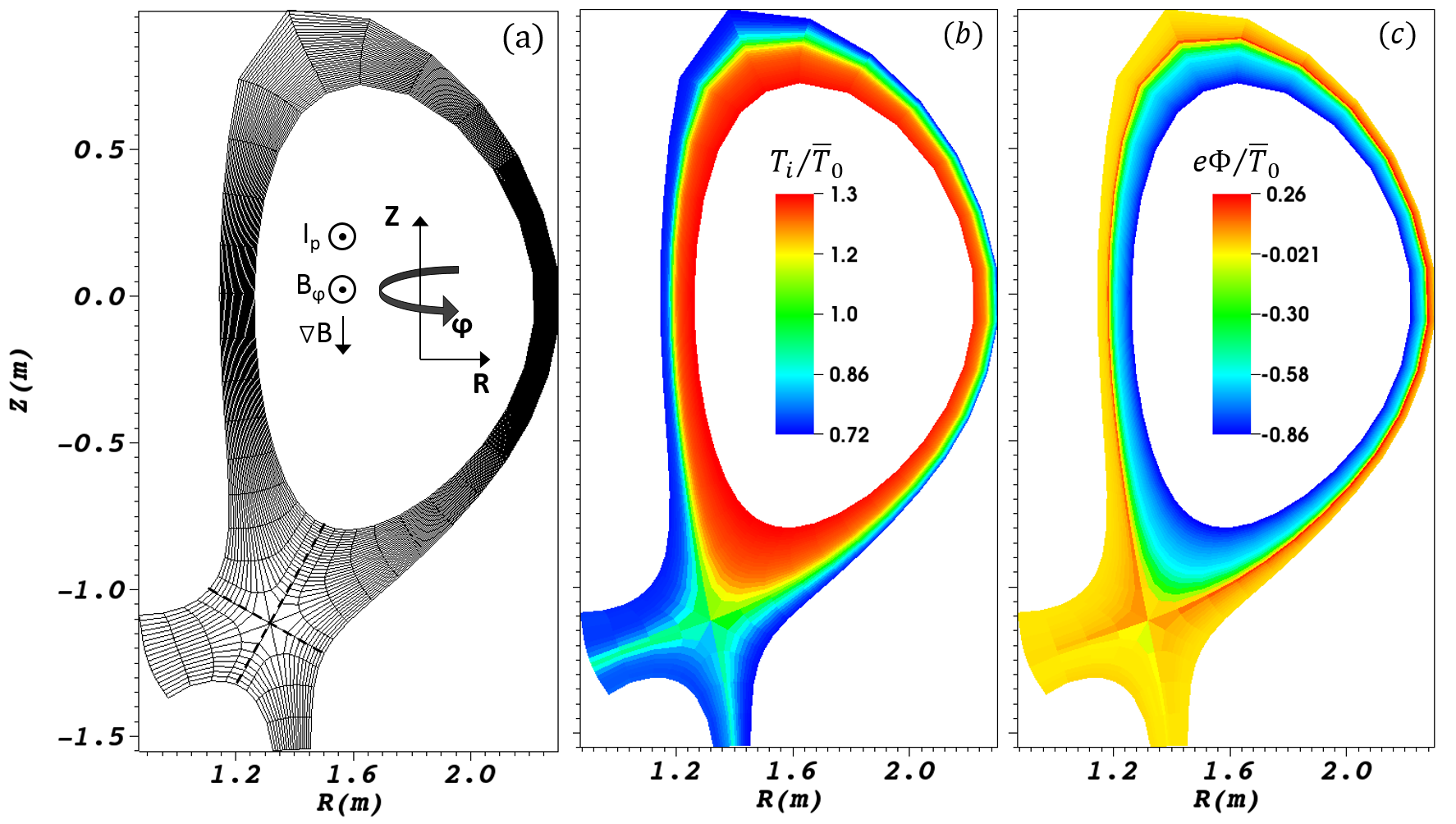
Our current and future algorithm work includes the development of sparse grid techniques to further improve the efficiency of our high-dimensional discretization, as well as the continued application of the ARK approach to address additional time scales. Our FEP partners are using COGENT for tokamak edge applications, whose range has been recently expanded to include problems addressed in the SciDAC Advanced Tokamak Modeling (AToM) and Plasma Surface Interaction (PSI2) collaborations. They are also extending the code for other magnetized plasma applications, such as Z-pinch plasmas, currently funded as part of an LDRD project. Given COGENT's unique continuum-based high-order approach in edge plasma geometries spanning both sides of the magnetic separatrix, we anticipate additional future impact in the MFE simulation community.
Contributors:
- CASC: Milo Dorr, Jeff Hittinger, Debo Ghosh, Lee Ricketson
- FEP: Mikhail Dorf, Ilon Joseph, Maxim Umansky, Vasily Geyko, Ron Cohen, Tom Rognlien
- LLNL Engineering: Justin Angus
- LBL: Phil Colella, Dan Martin, Peter McCorquodale, Peter Schwartz
Publications: See https://github.com/LLNL/COGENT/wiki/(9)-References
Contact: Milo Dorr
Path to Exascale | XPlacer: Data Placement Engine for Heterogenous Supercomputers

In the past few decades, there has been an influx in the use of Graphic Processing Units (or GPUs) to harness the massive computational power in the field of high performance computing. However, it is difficult for developers to obtain optimal performance for applications running on GPUs. One of the major reasons for this is because GPUs have a complex memory hierarchy consisting of different types of memories and caches, such as global memory, shared memory, texture memory, constant memory, and L1 and L2 caches. Each type of memory or cache is associated with its own characteristics such as capacities, latencies, bandwidths, supported data access patterns, and read/write constraints. Data placement optimization (i.e., optimizing the placement of data among these different memories) may have a significant impact on the performance of HPC applications running on GPUs. This type of optimization is an essential yet challenging step to exploit the abundance of GPU threads. We present a compiler/runtime system Xplacer to address this problem, and share results from our preliminary investigations into two orthogonal directions.
(i) Machine learning-driven data placement optimization.[1]
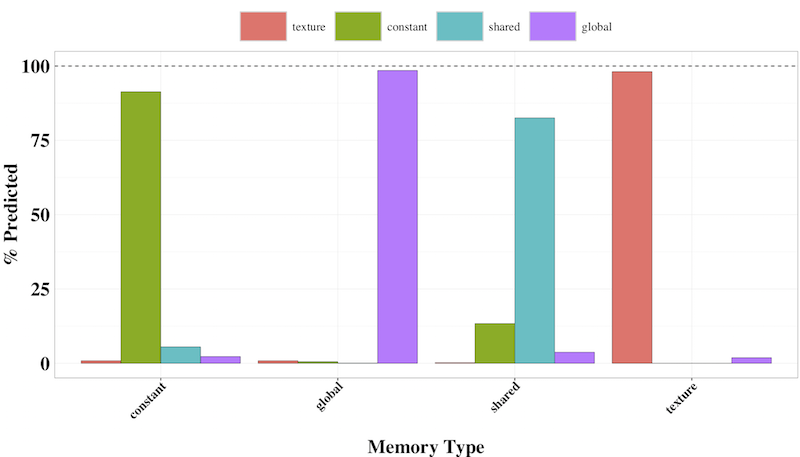
At the core of Xplacer is an online data placement engine that automatically determines the best data placements at runtime. This engine is based on a machine learning-based classifier to determine the best class of GPU memory that will minimize GPU kernel execution time. Initially, we built a supervised-learning based classifier that identifies which of the memory variants, i.e., global, constant, texture and shared, yields best performance, given only the default global variant. This approach utilizes a set of performance counters obtained from profiling runs and combines these with relevant hardware features to make this decision. We evaluated our approach on several generations of NVIDIA GPUs, including Kepler, Maxwell, Pascal, and Volta, on a set of benchmarks. The results, as shown in the figure below, demonstrate that the classifier achieves prediction accuracy of over 90%, and given the default global version, the classifier can accurately determine which data placement variant would yield the best performance.
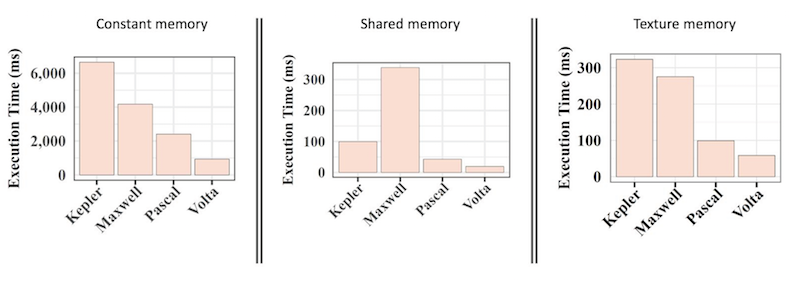
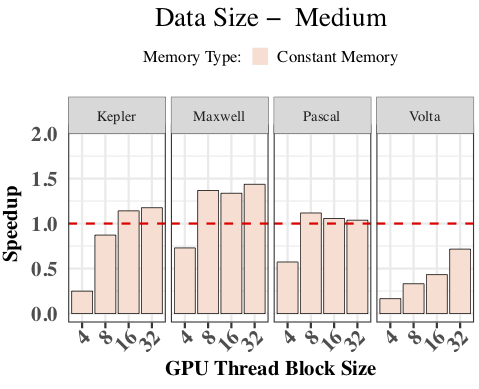
(ii) Understanding the relevance of data placement optimization on newer GPUs.[2]
Latest generations of GPUs introduce new memory properties or implement the same memories using a different physical structure and organization. We designed experiments to explore the impact of data placement optimization on several generations of NVIDIA GPUs (Kepler, Maxwell, Pascal, and Volta) and different codes, including a set of microbenchmarks, CUDA kernels, and a proxy application, LULESH.
Our key findings include:
- All types of memories on newer GPUs have improved performance compared to previous generations.
- The unified cache design of Volta GPUs helps narrow the performance gap between the default global memory and all other special memories. In particular, constant memory and texture memory seemed to be much less important on recent GPUs.
- Of those applications that benefited, texture and shared memory showed the most promise of speedup gain through considered data placement optimization.
- The memory properties of special memories significantly limit their use in real applications as they require significant code refactoring.

[1] “Data Placement Optimization in GPU Memory Hierarchy using Predictive Modeling," Larisa Stoltzfus, Murali Emani, Pei-Hung Lin, and Chunhua Liao, Workshop on Memory Centric High-Performance Computing, (MCHPC 2018).
[2] “Is Data Placement Optimization Still Relevant On Newer GPUs?" Abdullah Bari, Larisa Stoltzfus, Pei-Hung Lin, Chunhua Liao, Murali Emani, and Barbara Chapman, Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems, (PMBS 2018).
Contact: Chunhua "Leo" Liao, Pei-Hung Lin
Other contributors: Murali Emani, Abdullah Bari (Stony Brook University), and Larisa Stoltzfus (University of Edinburgh)
Looking back... LLNL's Legacy in the SC Conference

We opened this newsletter with an overview of CASC activities at the SC18 conference this year, but did you know that LLNL's George Michael was one of the founders and key organizers of the first SC (then called "Supercomputing") conference series? His legacy in HPC and on the SC conference is forever remembered in the ACM-IEEE CS George Michael Memorial HPC Fellowships that are awarded each year during the conference. While George unfortunately passed away in 2008, he left behind a great article capturing the early days of Supercomputing at LLNL that is a must read for anyone interested in supercomputing history.

In addition, several LLNL leaders in HPC have chaired the SC conference over the years, including Bob Borchers (LLNL Computation Associate Director, 1983–1991) in 1993, Dona Crawford (LLNL Computation Associate Director, 2001–2016) in 1997, Jim McGraw (CASC alumnus) in 2003, and Trish Damkroger (LLNL Computation Principal Deputy Associate Director, 2011–2016) in 2014.
Ever since the founding of CASC in 1996, we have played a significant role in each of the SC conferences (too numerous to summarize here!), with CASC members leading and serving on a variety of Program Committees, presenting outstanding and impactful technical research, leading numerous workshops and tutorials and BOFs, and helping make the SC conference the high-quality institution that it has become in the field of HPC.
CASC Highlights
New Postdocs
- Paul Tranquilli
- Will Pazner
- Milan Holec
- Giorgis Georgakoudis
- Qunwei Li
New Staff Hires
- Stephen Chapin
- Peter Pirkelbauer
Recent Award Highlights
- Timo Bremer, Abhinav Bhatele, and Erik Draeger are part of a select group to earn the 2018 LLNL Early-Mid Career Award.
- LLNL Outstanding Mentor Awards go to CASC Abhinav Bhatele, Annirudha Marathe, Harshitha Menon, and Barry Rountree.
- Ignacio Laguna was selected as a 2019 Better Scientific Software Fellow recognizing his leadership and advocacy of high-quality scientific software.
CASC Newsletter Sign-up
Was this newsletter link passed along to you? Or did you happen to find it on social media? Sign up to be notified of future newsletters, which we release approximately every 3–4 months.
LLNL-WEB-765161