
Disclaimer: This article is more than two years old. Developments in science and computing happen quickly, and more up-to-date resources on this topic may be available.
In This Issue:
- From the Director: My Vision for CASC
- Lab Impact: Large-Scale Graph Processing
- Advancing the Discipline: DataRaceBench: A Benchmark Suite for Systematic Evaluation of Data Race Detection Tools
- Path to Exascale: Enabling Ubiquitous Performance Analysis with Caliper
- Looking Back: A Brief History of SUNDIALS
- Highlights
From the Director
(Editor's note: Jeff Hittinger was named the new Director for CASC in March 2018)

I would like to take this opportunity to say a little bit more about my vision for CASC. CASC is the nexus for research within the LLNL Computation Directorate, with the mission of advancing the state of the art in scientific computing in pursuit and support of the programmatic goals of the Laboratory. This role will not change, but it is perhaps more important than ever before for the Laboratory that CASC delivers, influences, and leads.
The nature of scientific computing is evolving, and CASC must continue to evolve to meet each new challenge. We have seen HPC hardware evolve from specialized computers and vector processors to large collections of distributed, general-purpose commodity processors to a mixture of distributed, general-purpose processors and accelerators. The future promises even more heterogeneity in processors, accelerators, memory, and connectivity. Similarly, the application space has grown from interpretive forward simulations, to predictive simulations with quantified uncertainty, to design and inverse problems of increasing fidelity. The rapid rise of data science introduces both new applications and new opportunities to synthesize simulation and analysis, ultimately creating a more productive workflow for scientists, engineers, and analysts.
These developments are exciting. With the new challenges they present, they also offer tremendous opportunities to invent new algorithms, to leverage learned automation, and to develop improved workflows that will more tightly couple experiment, simulation, and theory – thus accelerating scientific discovery. Imagine the end-to-end benefits data analytics can provide from managing the power, performance, and scheduling of HPC systems, to managing task and distributed data layout to hardware better suited to individual tasks, to adapting algorithms and their parameters to accelerate computation, to providing intelligent in situ identification of data for output, to managing adaptively the exploration and interpretation of solution and parameter spaces in design and decision processes. Supporting these complex workflows will be configurable confederations of capabilities including heterogeneous HPC platforms, databases, cloud computing resources, message brokers, and even experimental facilities working in a tightly coupled fashion to accelerate analysis and discovery. How this coalescence of ideas and technologies occurs is up to us, and CASC needs to lead Computation, LLNL and its programs, and the scientific community into this future.
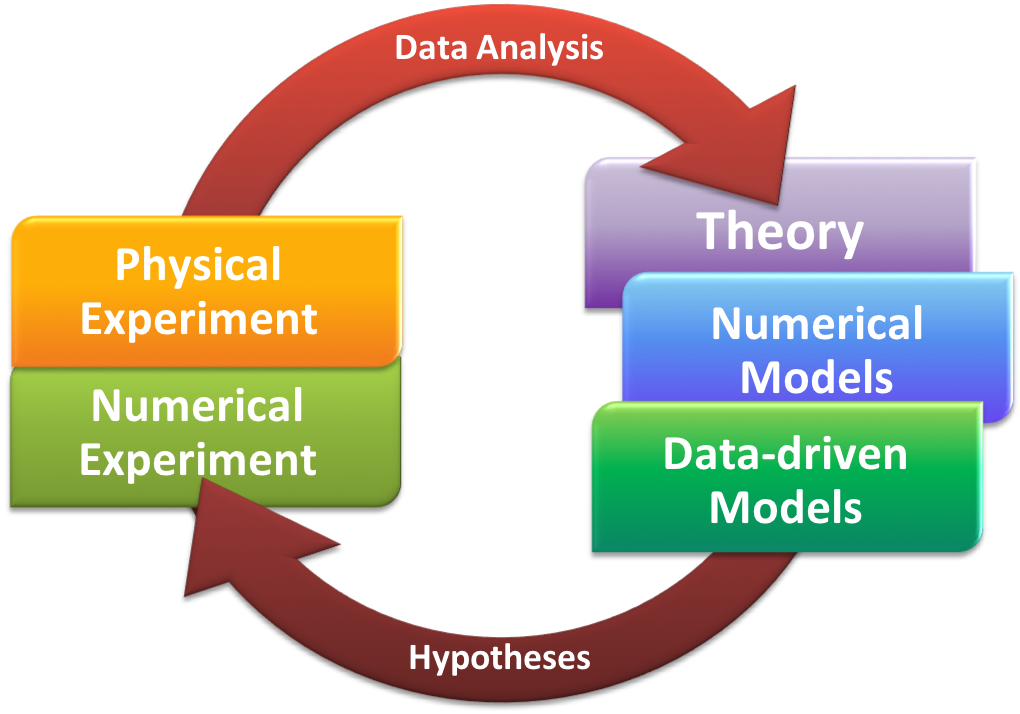
A strength of the people in CASC is our adaptability. We will continue to push forward the cutting edge capabilities in scientific computing, incorporating new ideas and approaches from the expanding field of data science. We will not forsake our traditional strengths in computer science and computational mathematics and physics but will learn to augment our approaches with the help of data science colleagues – those with whom we have worked for years and experts new to the Laboratory. We will advance the field of data science, reinforcing its foundations and establishing its role in the breadth of the Laboratory’s national security mission. More than ever before, the challenge before us lies at the intersection of many domains, and this is the perfect opportunity to build closer ties across disciplines within CASC and with our colleagues throughout the Laboratory.
Contact: Jeff Hittinger
Lab Impact | Large-Scale Graph Processing
CASC researchers Roger Pearce and Geoffrey Sanders lead a team that is driving new capabilities for large-scale graph processing on HPC. Ever increasing data volumes from analysis and security applications involving global-scale information systems (social networks, financial systems, enterprise networks, internet services, infrastructure) demand increasing capabilities for data processing, and graph analysis (also known as complex network analysis) is an important facet. Efficient HPC graph analysis is of particular interest to many sponsoring agencies that require rapid extraction of anomalies from such datasets. Many of the techniques developed by their team are being leveraged by externally sponsored projects. Several of the algorithmic and systems enhancements the team has recently developed improve and even expand previously existing capabilities to datasets 2–3 orders of magnitude larger (to terabyte scales), including graph pattern matching, centrality ranking, and triangle counting.

Along with collaborators at University of British Columbia, their team developed a novel pattern matching algorithm called PruneJuice [1,2], that is capable of pattern matching within trillion-edge graphs on HPC systems. The approach recursively prunes large graphs, revealing the exact location of an input query pattern – or determines if the query is absent. The team is further developing HPC fuzzy pattern matching, returning subgraphs that almost match the query pattern, and creating adaptive algorithms for further increases in efficiency.
Another capability recently developed comes from the team’s post doc, Keita Iwabuchi. Keita has developed a technique to calculate the eccentricity of all vertices in a large graph [3]. Eccentricity is a one of many metrics of vertex centrality, and Keita’s work involves theoretical, algorithmic, and implementation innovations to yield improved approximation of eccentricity and with more efficiency on HPC systems. Keita is working to extend this success to other related centrality computations.
Finally, motived by the IEEE/DARPA Graph Challenge, the team has demonstrated the largest calculations of triangle-counting and k-truss decomposition on real-world datasets [4]. Triangle-counting and k-truss are critical calculations used to analyze community structure in large graphs, and considered a fundamental challenge problem for data-intensive computing.
The open-source graph toolkit can be found here: http://software.llnl.gov/havoqgt.
Publications:
[1] T. Reza, C. Klymko, M. Ripeanu, G. Sanders, and R. Pearce, “Towards practical and robust labeled pattern matching in trillion-edge graphs,” in 2017 IEEE International Conference on Cluster Computing (CLUSTER), Sept 2017, pp. 1–12.
[2] T. Reza, Ripeanu, N. Tripoul, G. Sanders, and R. Pearce, “PruneJuice: Pruning Trillion-edge Graphs to a Precise Pattern-Matching Solution,” in 2018 Supercomputing (SC18), to appear.
[3] K. Iwabuchi, G. Sanders, K. Henderson, and R. Pearce, “Computing Exact Vertex Eccentricity on Massive-Scale Distributed Graphs,” in 2018 IEEE International Conference on Cluster Computing (CLUSTER), to appear.
[4] R. Pearce, “Triangle Counting for Scale-Free Graphs at Scale in Distributed Memory,” in 2011 IEEE High Performance Extreme Computing Conference (HPEC), 2017, pp. 1-4.
Contact: Roger Pearce
Advancing the Discipline | DataRaceBench: A Benchmark Suite for Systematic Evaluation of Data Race Detection Tools
A data race happens when two threads are concurrently accessing a shared memory location (at least one of the accesses is a write access) without proper synchronization. Due to nondeterministic behaviors of multi-threaded parallel programs, data races are notoriously damaging while extremely difficult to detect. OpenMP is a popular parallel programming model for multi-threaded applications in high performance computing. Many tools have been developed to help programmers find data races in OpenMP.
DataRaceBench is the first dedicated OpenMP benchmark suite designed to systematically and quantitatively evaluate the effectiveness of data race detection tools. Its latest version (v 1.2.0) includes 116 microbenchmarks with and without data races. These microbenchmarks are either manually written, extracted from real LLNL scientific applications, or automatically generated optimization variants.

Using DataRaceBench, we have evaluated four mainstream data race detection tools: Helgrind, ThreadSanitizer, Archer, and Intel Inspector. The evaluation results show that DataRaceBench is effective to provide comparable, quantitative results and discover strengths and weaknesses of the tools being evaluated. In particular, we have found that:
- OpenMP-awareness is necessary for a tool to reduce false positive reports.
- Results obtained from dynamic data race detection tools can be sensitive to tool configurations.
- Among the tools evaluated, only Intel Inspector consolidates multiple data race instances into one single pair of source locations.
- Multiple runs with varying OpenMP thread counts and scheduling policies are sometimes needed to catch data races.
- Existing OpenMP compilers do not generate SIMD instructions for our race-yes SIMD benchmarks. The tools relying on these compilers cannot detect SIMD level data races.
- 13 programs triggered Archer (part of the LLNL Pruners project) to have some compile-time or runtime errors. We are actively working with the Archer developers to address these issues.
- There is still room for improvements for Intel Inspector to find data races caused by task constructs such as taskloop, taskwait, and taskgroup.
To obtain the latest release: https://github.com/llnl/dataracebench.
Work funded by LDRD, Detecting Data-Races in High-Performance Computing, 17-ERD-023
Publications
Chunhua Liao, Pei-Hung Lin, Joshua Asplund, Markus Schordan, Ian Karlin. DataRaceBench: A Benchmark Suite for Systematic Evaluation of Data Race Detection Tools (Best Paper Finalist). SuperComputing 2017, Denver, CO, USA.
Chunhua Liao, Pei-Hung Lin, Markus Schordan and Ian Karlin, A Semantics-Driven Approach to Improving DataRaceBench's OpenMP Standard Coverage, IWOMP 2018: 14th International Workshop on OpenMP, Barcelona, Spain, September 26-28, 2018 (Accepted)
Contacts: Chunhua Liao, Pei-Hung Lin, and Markus Schordan
The Path to Exascale | Enabling Ubiquitous Performance Analysis with Caliper
To HPC software developers, conducting performance analysis often feels needlessly difficult because many current HPC performance analysis tools focus on interactive performance debugging and require complex, manual preparation steps. The Caliper project aims to make performance profiling easier and integrate it better into the software development process. Ultimately, its goal is to turn performance profiling from a manual task into a regular, automated part of application execution.
Caliper is a library that integrates a performance analysis tool stack into applications. It supports a wide range of performance engineering use cases, such as phase or function time profiling, MPI message tracing, or memory profiling. Typically, application developers mark application phases and other elements of interest using Caliper’s source-code annotation API. Performance measurements can then be configured at runtime by activating Caliper services, which implement specific measurement or data processing functionality. Because Caliper is built into the application, performance data collection is always available without additional preparation steps and can be enabled through regular application controls that are familiar to users, like input files or command line switches.
Caliper also simplifies the development and deployment of performance analysis tools. Building on top of Caliper’s already existing infrastructure, we can rapidly create new, specialized tools and employ them immediately in any Caliper-enabled application. This includes analysis tools such as the hatchet library for analyzing call tree profiles, and research tools such as the Apollo tuning framework. Caliper supports standardized output formats like JSON to facilitate analysis with general-purpose data analytics tools. There are also bindings to export Caliper source-code annotations to third-party vendor tools, such as Intel VTune or Nvidia NVProf. Thus, applications adopting Caliper can tap into a broad tool ecosystem.
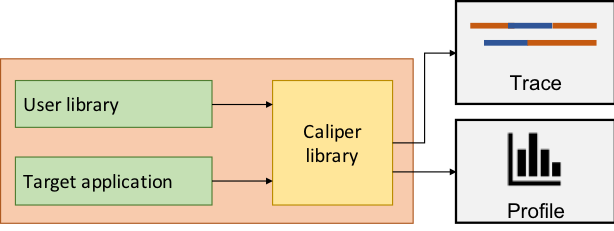
A major driver in Caliper’s adoption and development is the support for new, automated performance analysis workflows. Under the ubiquitous performance analysis model, we collect performance data for every run, including production runs as well as nightly or continuous integration tests. This allows us to build a comprehensive database of an application’s performance history, so we can detect regressions early on and evaluate the performance impact of code and system changes. Caliper provides input data for several projects that are currently underway at LLNL to build the ubiquitous performance analysis infrastructure. Prime examples are SPOT, a web-based frontend to browse and view application performance data collected over time, and Sonar, which collects Caliper data to correlate system and application-level information.
Caliper is funded in-part through the Exascale Computing Project.
Contact: David Boehme
Looking Back | A Brief History of SUNDIALS
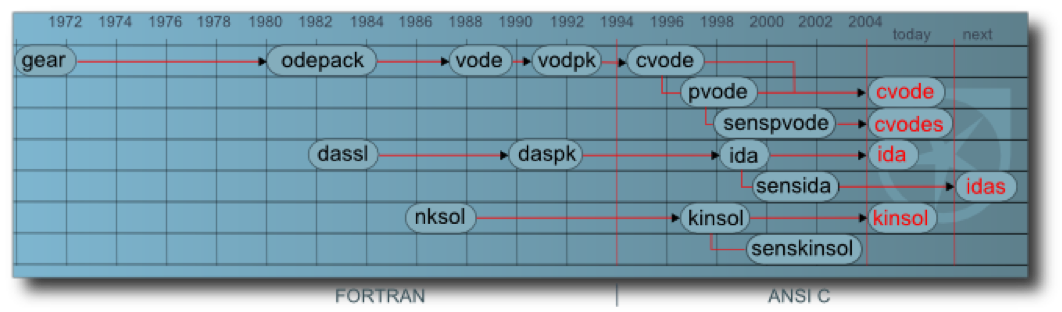
SUNDIALS originated in 1993 as a rewrite in C of two general purpose Fortran solvers for Ordinary Differential Equations, VODE and VODPK. These packages had evolved from some of the first and most heavily used ODE integrator packages ever developed, first available through the NETLIB FTP site as part of ODEPACK (which had more than 250,000 downloads). Based on linear multistep methods for both non-stiff and stiff systems, these solvers used adaptive time-stepping and variable-order schemes to deliver solutions whose error within each time step was bounded by user-supplied tolerances. The VODE line of codes represented a breakthrough in general purpose ODE integrators in that they used variable-coefficient multistep methods instead of fixed-step-interpolated methods. The variable coefficient form allowed for efficient solvers tuned through integrator heuristics. The goal of the 1993 rewrite was a version of these heavily used solvers that could be easily extended from serial to distributed memory parallel computers. The resulting serial code, called CVODE, was followed by a parallel version, called PVODE. The ease of making this conversion was achieved by the use of two sets of routines for basic vector operations, one serial and one parallel (based on MPI).
The success of the rewrite prompted a similar rewrite of a nonlinear algebraic systems solver, NKSOL, which was the first Newton-Krylov-based nonlinear software package, into the KINSOL package. (CNKSOL was voted out as a name due to a desire of LLNL management for a pronounceable package name, hence KINSOL, for Krylov Inexact Newton SOLver.) Further development of the common infrastructure led to a C rewrite of a pair of differential-algebraic system solvers, DASSL and DASPK, resulting in the IDA package. The original name for this group of three codes was “The PVODE Trio.” With careful encapsulation of data vectors, the codes were engineered so that the core integrator and nonlinear solvers were the same whether run in serial or parallel. With this advance, the “P” was replaced with “C” in the CVODE name making the PVODE Trio name obsolete. The group of packages were then given the acronym SUNDIALS, for SUite of Nonlinear DIfferential and ALgebraic equation Solvers, and first released under that name in 2002.
Extensions to the time integrators to handle forward and adjoint sensitivity problems, called CVODES and IDAS, were added later.

In 2015 a new ODE integration package, ARKode, was added to SUNDIALS. ARKode includes multistage methods which are better suited to time evolution systems posed within spatially adaptive codes than the multistep methods in CVODE. The six packages in SUNDIALS all share a collection of vector operation modules, which originally included serial and MPI-parallel versions. In 2015, versions supporting threaded environments were added, and GPU support through CUDA and RAJA was added in 2017. Recent extensions to SUNDIALS have included wrappers for PETSc and hypre vectors. Richer interoperability layers with those and other DOE solver packages are planned through the Exascale Computing Project.
A timeline of SUNDIALS development:
- 1982 - First release of ODEPACK
- 1986–1991 - Development of VODE and VODPK
- 1993 - Initial rewrite of VODE/VODPK into CVODE
- 1994 - CVODE first released
- 1995 - Initial version of PVODE written
- 1998 - PVODE first released
- 1998 - KINSOL first released
- 1999 - IDA first released
- 2002 - First release of SUNDIALS under a BSD license
- 2004 - CVODES first released
- 2009 - IDAS first released
- 2015 - ARKode first released as part of SUNDIALS
- 2016 - Changed procedures to allow for unregistered downloads
- 2017 - Created GitHub mirror of released software for download
For much more information about SUNDIALS, documentation, and downloads: https://computing.llnl.gov/projects/sundials.
Contact: Carol Woodward
SUNDIALS Team:
- (Current): Alan C. Hindmarsh, Carol S. Woodward, Daniel R. Reynolds (SMU), David J. Gardner, Slaven Peles, Chris Vogl, and Cody Balos.
- (Alumni): Radu Serban, Scott Cohen, Peter Brown, George Byrne, Allan Taylor, Steven Lee, Keith Grant, Aaron Collier, Eddie Banks, Steve Smith, Cosmin Petra, John Loffeld, Dan Shumaker, Ulrike Yang, Hilari Tiedeman, Ting Yan, Jean Sexton, and Chris White
CASC Highlights
New Postdocs (Since April 2018)
- Tristan Vanderbruggen
- Delyan Kalchev
- Hillary Fairbanks
- Eisha Nathan
- Ben Yee
- Quan Bui
New Hires (conversion from postdoc, since January 2018)
- Debojyoti Ghosh
- Ruipeng Li
- Nikhil Jain
- Bhavya Kailkhura
- Tapasya Patki
- Anirrudha Marathe
- Rushil Anirudh
Also, Ana Kupresanin joins us as an internal LLNL transfer from the Engineering Directorate as the new Deputy Division Leader for CASC. Welcome Ana!
CASC Newsletter Sign-up
Was this newsletter link passed along to you? Or did you happen to find it on social media? Sign up to be notified of future newsletters, which we release approximately every 3–4 months.
LLNL-WEB-756861