
Able to extract data, extrapolate results, and accelerate processes faster than humanly possible, artificial intelligence (AI) and machine learning (ML) algorithms have become crucial tools in scientific discovery. But are these models safe to use in mission-critical scenarios involving classified information or where lives may be at stake? Livermore’s AI/ML experts are finding out.
Tasked with a range of national security objectives, LLNL is advancing the safety of AI/ML models in materials design, bioresilience, cyber security, stockpile surveillance, and many other areas. A key line of inquiry is model robustness, or how well it defends against adversarial attacks. A paper accepted to the renowned 2024 International Conference on Machine Learning explores this issue in detail.
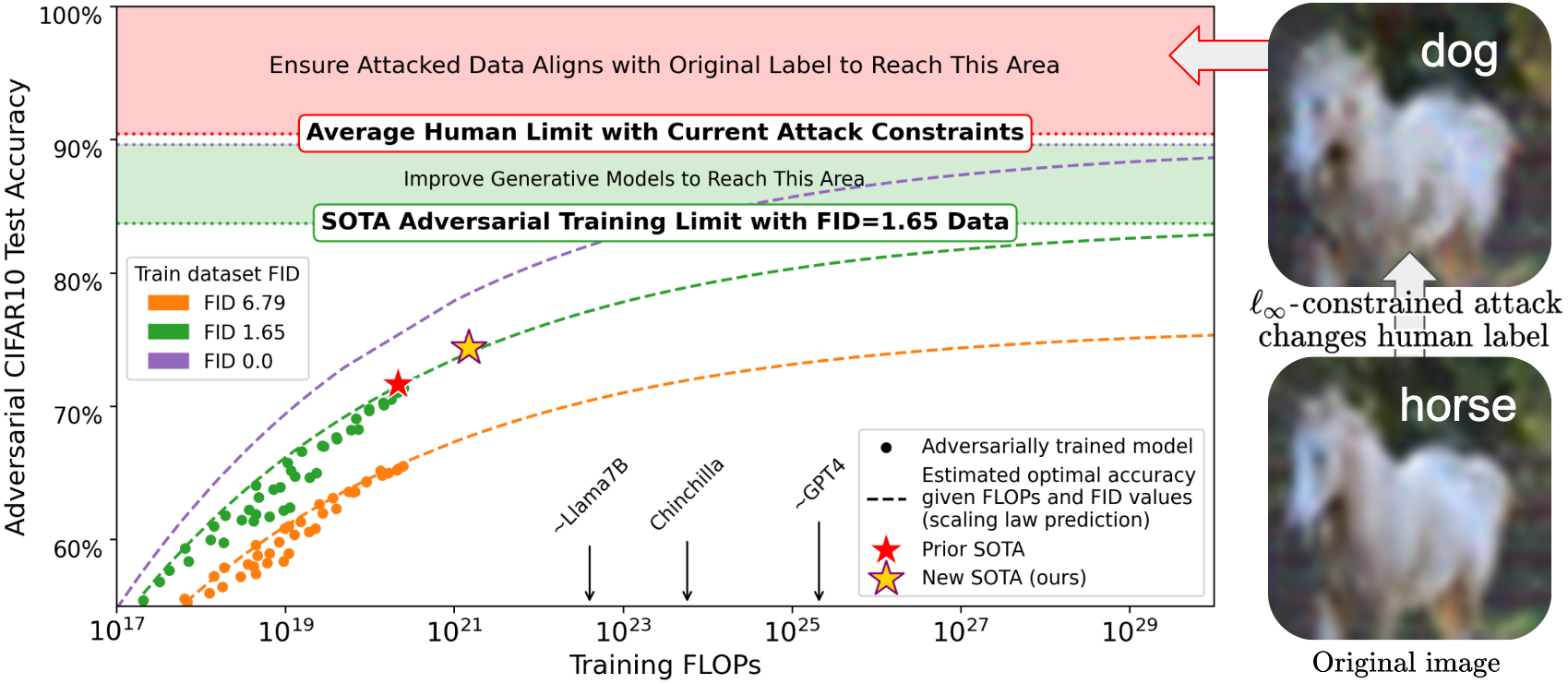
Generally, AI/ML model performance improves as scale increases—more data, more parameters, more compute. However, Brian Bartoldson points out that a model’s safety and robustness, or lack thereof, did not have as clear a relationship with its scale prior to their work. “A larger model may have more vulnerabilities, or more compute power might not help it fend off attacks,” he says.
Models that classify images are particularly vulnerable to attacks. Even tiny perturbations to color, texture, or other features can fool a model into identifying a horse as a dog. Bartoldson explains, “Classifiers are exposed to a finite set of images during training without seeing all variations of the horse. So, after training, the model has a good sense of what a horse looks like but might not be robust to slight changes in pixels. This gap in the training dataset allows the model to be attacked.”
In “Adversarial Robustness Limits via Scaling-Law and Human-Alignment Studies,” Bartoldson, James Diffenderfer, Konstantinos Parasyris, and Bhavya Kailkhura studied the effect of scaling robust image classifiers—using a method called adversarial training—to develop the first scaling laws for robustness. The team’s adversarial training approach alters pixels where the model seems most vulnerable, thus providing the model with a more continuous view of the data distribution. The work was funded by the Laboratory Directed Research and Development program.

State-of-the-art approaches had found anecdotal evidence that scaling the dataset sizes and model sizes used during adversarial training improved robustness. But when tested on the public CIFAR-10 dataset, which is commonly used to train image classifiers, the best robustness methods had only managed about 70% success against attacks. To produce their scaling laws, the LLNL team expanded the traditional paradigm of considering dataset and model sizes to include dataset quality, then systematically analyzed how all three variables affected the robustness of models they had adversarially trained.
Data quality is measurable using the Fréchet Inception Distance (FID) score, which compares synthetically generated images to actual images from the target dataset. Researchers trying to solve the image robustness problem often generate tens of millions of synthetic data points to augment CIFAR-10’s 50,000 model training images.
Bartoldson and colleagues took the usual process a step further and varied the quality of their synthetic images, then noted how robustness corresponded to the synthetic image quality (measured by FID score). He states, “We wanted to figure out how much data quality mattered. Does the synthetic training data need to look exactly like the CIFAR-10 data in order to produce a model that is robust against attacks?”
As it turns out, better data quality provides significant benefits to the robustness produced by adversarial training—up to the point where images from the synthetic dataset are so high quality that they could pass as images from the actual dataset. Further emphasizing the importance of data, models smaller than those used in prior research were highly robust as long as they saw a sufficient amount of high-quality data. The team improved on the state of the art to 74% adversarial robustness and outperformed it with a model three times smaller that saw three times more data.
The new scaling laws are equations that predict robustness against unseen attacks, given model size and training dataset quality and size. They can be used to recommend optimal allocations of compute resources and identify opportunities for reducing inefficiently large models. In particular, researchers can specify requirements (on factors like model size, dataset size, and compute), then ultimately deploy more robust models that quickly and efficiently meet their requirements.
AI/ML model robustness will always be relevant in mission-critical settings. For example, Bartoldson suggests, “Imagine an attacker looking for sensitive information in order to create a weapon. A model may be trained to withhold that information, but the attack could eventually coax the model to do what it wants. You don’t want models to be susceptible to attackers’ tricky input perturbations in the wild.”
—Holly Auten