
The widespread use of artificial intelligence (AI) and machine learning (ML) reveals not only the technology’s potential but also its pitfalls, such as how likely these models are to be inaccurate. AI/ML models can fail in unexpected ways even when not under attack, and they can fail in scenarios differently from how humans perform. Knowing when and why failure occurs can prevent costly errors and reduce the risk of erroneous predictions—a particularly urgent requirement in high-consequence situations.
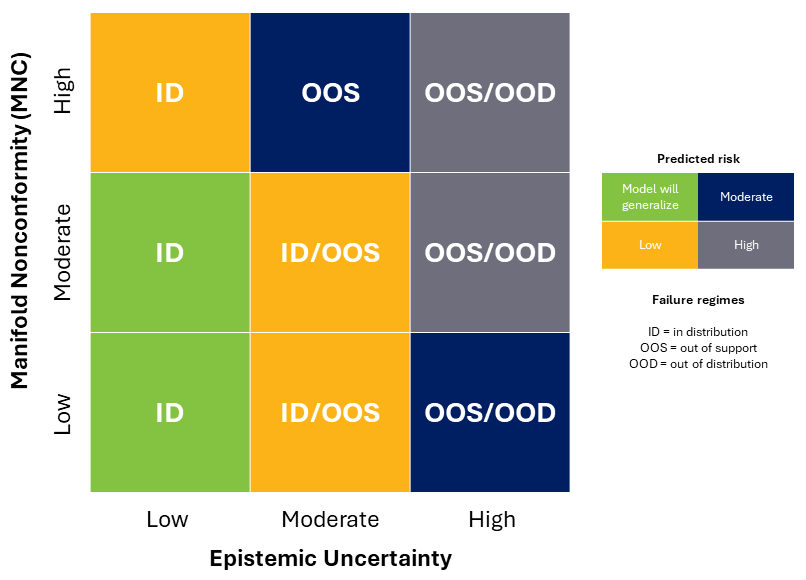
LLNL researcher Vivek Narayanaswamy, alongside former employee Jayaraman Thiagarajan and collaborators from the University of Michigan and Amazon, tackled the problem of detecting failures in a paper accepted to the 2024 International Conference on Machine Learning. In “PAGER: Accurate Failure Characterization in Deep Regression Models,” the team categorized model risk into three regimes: in distribution, out of support (data similar to training data), and out of distribution (unforeseen data). Their analysis spawned the PAGER framework—Principled Analysis of Generalization Errors in Regressors—which systematically detects failures and quantifies the risk of failure in these regimes.
Before PAGER, researchers measured model failure in terms of epistemic uncertainty, or the model’s likelihood of failure with insufficient training data. But this approach doesn’t uncover all the nuances of the failure regimes. For instance, low uncertainty might not correspond to low risk in a particular situation.
Instead, PAGER combines epistemic uncertainty estimates with novel manifold nonconformity (MNC) scores derived from a single model. The proposed MNC measures a model’s ability to discern discrepancies within the training data. To estimate both of these scores, PAGER leverages a training method called anchoring which is a popular method developed at LLNL for single model uncertainty estimation and extrapolation.
Narayanaswamy states, “Anchoring allows our tool to work on different types of ML architectures, such as classifier or regression models. And PAGER can be used on any type of data whether it’s text, images, time series, graph structured, or something else.”
Together, the epistemic uncertainty and MNC scores expose insufficiencies and inconsistencies that can cause a model to fail in any of the regimes. When faced with varying data distributions in benchmarking datasets, PAGER consistently outperforms state-of-the-art epistemic uncertainty methods.
In addition to this innovative scoring method, the team’s solution detects failures on the fly without human supervision—a necessary feature in the real world. For instance, an airport luggage scanner evaluates each bag and moves on, making decisions quickly and repeatedly. “Failure detection must be built into a model’s training and deployment,” Narayanaswamy points out.
Another key aspect of PAGER’s effectiveness is its proactive approach to failure detection (i.e., effectively anticipating failure risk). By assessing a model’s risk before failure occurs, PAGER can help it decide which safety mechanism to use and thus build failure resilience over subsequent iterations.
Livermore scientists are beginning to use the PAGER framework in an autonomous multiscale simulation project, funded via the Laboratory Directed Research and Development program. In a large-scale multiphysics simulation, an ML model can act as a surrogate for distinct time steps in the overall computation. Standing in for subscale calculations, these surrogates will rely on PAGER to detect failures in real time. If a failure is detected, the simulation can pivot to call the physics code for that time step, then move on to the next one. If there’s no failure, the simulation can progress seamlessly. In this way, PAGER-augmented surrogate ML models can improve the overall safety of ML-driven pipelines at the Lab.
—Holly Auten