
Disclaimer: This article is more than two years old. Developments in science and computing happen quickly, and more up-to-date resources on this topic may be available.
CASC has steadily grown its reputation in the artificial intelligence (AI)/machine learning (ML) community—a trend continued by three papers accepted at the 35th AAAI Conference on Artificial Intelligence, held virtually on February 2–9, 2021. Computer scientists Jayaraman Thiagarajan, Rushil Anirudh, Bhavya Kailkhura, and Peer-Timo Bremer led this research.
“Unlike large corporations with staff dedicated to publishing, we have limited resources for writing and submitting papers. To make our mark in this field, at a conference like AAAI, is a big deal for our small team,” notes Bremer. CASC director Jeff Hittinger adds, “It is important that our outstanding researchers receive this kind of recognition by the ML community because it demonstrates that we are not only applying machine learning to our challenging mission problems but also pushing the frontiers of ML methodologies.”
Unique Scientific Challenges
A key research question in AI centers on the integrity—or robustness—of ML models: How can we trust a model’s predictions? Answering this question means understanding how a model works, how it responds to new data variables, how it behaves under attack (from natural data perturbations to deliberate data corruption), and more. A model’s robustness can be understood by probing the scope of its interpretability and explainability. The CASC team’s AAAI papers tackle robustness from different angles: feature importance estimation under distribution shifts, attribute-guided adversarial training, and uncertainty matching in graph neural networks. (Preprints are linked.)
In scientific applications pursued at the Lab, Kailkhura explains, “We have unique challenges like small or complex data problems. There’s a higher chance of something going wrong with the model.” This scenario is known as high regret. LLNL’s mission areas include high-regret scientific applications in materials science, threat detection, inertial confinement fusion, and healthcare—to name only a few.
“Robustness is a fundamental building block of our ML research,” Kailkhura continues. “If a movie recommendation algorithm makes an incorrect prediction, the customer is negatively impacted for only a short time. But if our model misclassifies a radioactive material, humans can potentially be harmed. The consequences are much higher in scientific use cases.”
Although every scientific problem has its own data, the team aims for solutions that can be effectively applied to multiple scenarios and data modalities. Thiagarajan, who co-authored all three papers, notes that using a model’s predictions to make decisions also poses a challenge. “Scientists base their decisions on a model’s output, so we must rigorously characterize how a model fails and succeeds,” he says.
The solutions presented in the three AAAI papers were tested against—and consistently outperformed—state-of-the-art benchmarks. Thiagarajan points out, “In this rapidly growing field, you need to benchmark against the latest and greatest in order to make advances.” Kailkhura adds, “These problems are so difficult that no single paper solves them. We are taking incremental steps, and challenging other methods helps us gauge how far we’ve come.”
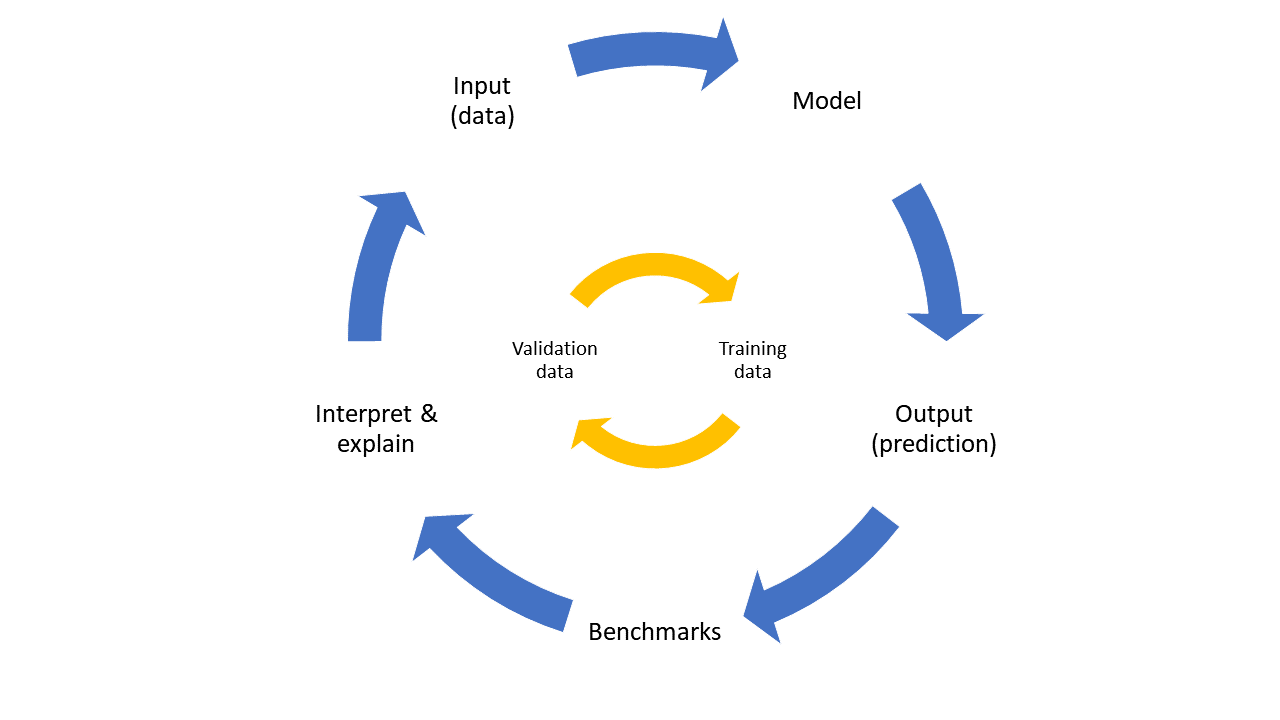
Explaining the Black Box
Many highly complex ML models are described as black boxes, where inputs (data) and outputs (decisions) are known but without insight into how the model functions. Feature importance estimation is a popular approach for black box interpretability, which weighs the influence of different inputs on the model’s output.
Thiagarajan explains, “Feature importance estimation means finding the model’s focus, such as the most meaningful pixels in an image that correctly identify the subject. The model will fail if those features are removed.” Bremer adds, “We need to know on which basis the model makes decisions so we can also catch its mistakes.”
The CASC team created a computationally efficient technique called PRoFILE—Producing Robust Feature Importances using Loss Estimation—that estimates feature importance scores without additional model re-training. PRoFILE is comprised of an optimized loss estimator in addition to the predictive model, which quantifies the difference between actual and predicted outputs, and it accurately detects distribution shifts, which characterize the difference between the training and validation datasets.
According to Thiagarajan, “A robust model will have a consistent explanation even when there are changes in the data distribution.” The PRoFILE research examines learning strategies that train the loss estimator for any data modality, deep learning architecture, or task. For example, the estimator can identify a dog in a photo based on the shape of the nose. If the image is blurred, the model can still predict that the image shows a dog by looking for another dog-like feature.
Strengthening the Training Data
Robust ML models should be able to make predictions on unseen data samples—those not represented by samples within the training dataset. Adversarial training, which supplies deceptive inputs, can help models learn to interpret data better by introducing small perturbations. For instance, image classification algorithms can learn from changes in image quality (such as blurring), on individual pixels, on objects within the image, and other noise.
The CASC team developed an approach called Attribute-Guided Adversarial Training (AGAT), where the ML model learns to generate new training samples and, therefore, maximize the image classifier’s exposure to attributes beyond the initial dataset. In other words, AGAT expands the training dataset’s variety in the number and types of perturbations introduced.
Surrogate functions are a key part of this robustness approach. These functions are used to approximate image manipulators found in real-world scientific domains. Anirudh explains, “We must supply domain knowledge to an ML model that relies only on simulated data. A surrogate function acts like a domain expert to tell the model how simulated and real-world data are different.”
Kailkhura describes an example of a drone used to complete surveillance tasks. Its ML algorithm performs object detection and classification based on a training dataset of specific environments, such as forest fires. The drone may need to conduct surveillance of a snowy mountain without having trained on images of snow. He says, “The surrogate-enhanced model takes the prior knowledge of the environment into account to train the drone on the new environment.” AGAT lets the model figure out which data is useful, yielding better results.
Defending against Poisoning Attacks
Another type of adversarial training involves a poisoning attack, where the training dataset is tainted with corrupt data. These attacks can expose vulnerabilities in graph neural networks (GNNs), which operate on graph-structured data and are used in scientific analysis of biological networks, brain connectomes, molecular data in drug discovery and materials design, and more.
Thiagarajan states, “Datasets are never perfectly clean. There is always some noise. We can use the model’s uncertainties to estimate which parts of the graph are noisy versus which parts can be trusted, thus reducing GNN vulnerability.”
The third CASC paper describes an Uncertainty Matching Graph Neural Network (UM-GNN) technique that defends against poisoning attacks by quantifying prediction uncertainties during training. UM-GNN uses semi-supervised learning in which a second generation of the ML model extracts knowledge from the first generation’s uncertainties. Thiagarajan offers an analogy of a student learning from a teacher. He explains, “When uncertainties are large, the student doesn’t trust the teacher and is better off learning on its own. The student model ends up being much more robust than the teacher model.”
Next-Gen Researchers
The team’s papers were co-authored with six Arizona State University (ASU) students who interned at the Lab during the summer of 2020. ASU is one of several university partners conducting collaborative research with CASC, and these relationships are beneficial to all parties. Bremer states, “We find academic departments that work well with us, where faculty members commit to long-term projects and we can help guide student projects. ASU is a very good partner in the ML field.”
ASU in particular has been a valuable workforce pipeline for CASC; Thiagarajan and Anirudh earned their PhDs from ASU in 2013 and 2016, respectively. CASC director Jeff Hittinger states, “Computing’s student internship program is the most direct way for our directorate to raise awareness of careers at the national labs. Engaging students in our cutting-edge research has proven to be one of the most effective means to excite them about research in the national interest.”
—Holly Auten