
In virtually all mission-critical applications—such as high-energy-density physics, material science, Earth system modeling—the phenomena of interest are dependent on a wide range of length and timescales that cannot be fully resolved in a single simulation. Instead, the problem is typically formulated at the largest scale necessary—for example, an entire facility, device, or manufactured part—and finer scales are represented through so-called subscale models. These subscale models approximate processes such as atomic physics, grain-scale responses, and chemical kinetics, among many others.
But these subscale codes themselves also use approximations of even finer scales, creating a nested hierarchy of models that can range from planetary scale to first-principles quantum simulations. In the simplest and most common usage pattern, subscale models are called at each time step at each grid element in the primary simulation, and thus can quickly dominate the runtime of the entire application. In practice, scientists routinely must balance the desired fidelity of these subscale models with the available compute resources. Ultimately, the achievable accuracy is strictly limited by the corresponding costs.
One potential solution to this challenge is to replace the expensive physics evaluations with significantly cheaper statistical surrogates trained on data from the appropriate libraries. Researchers have successfully used recent deep learning models to formulate models for virtually any data type including images, spectra, and a host of other modalities, making it possible to replace arbitrary subscale models. However, even assuming reliable training, these models are known to generalize poorly to unseen data and to fail silently if problems arise. At best, researchers can quickly re-compute use cases for which training data exist, such as a situation in which a high-fidelity traditional simulation has already been executed. While useful in many cases, this paradigm does not allow a fundamental acceleration or increase in fidelity beyond what is currently possible without risking silent corruption of the results.
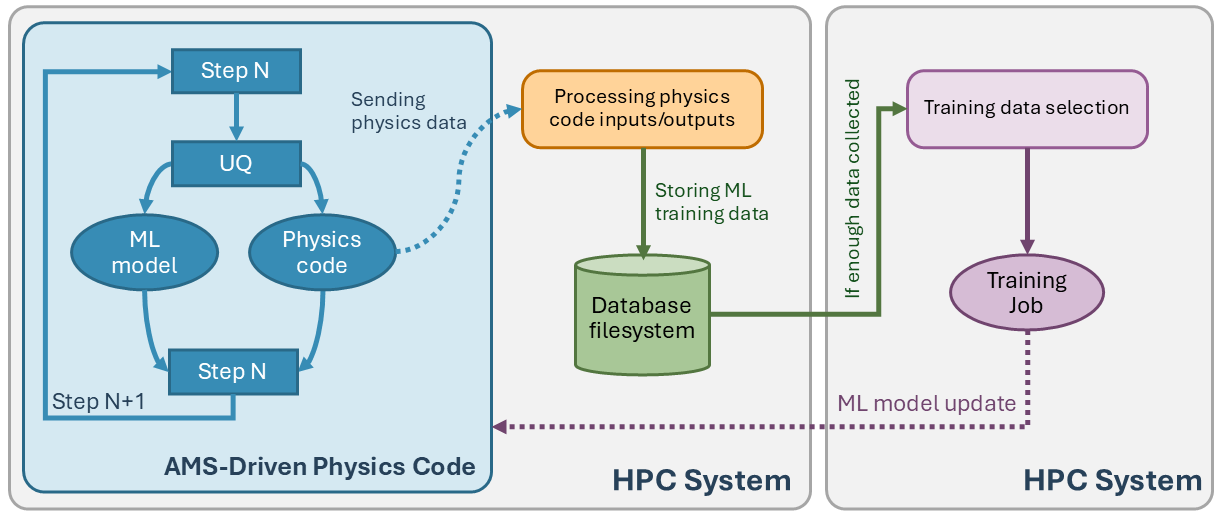
LLNL’s Autonomous Multiscale Simulation (AMS) Strategic Initiative has demonstrated an alternative strategy built on a combination of software engineering, trustworthy machine learning, and advanced modeling to make multiphysics simulations faster, more accurate, and portable—faster by replacing expensive evaluations with reliable surrogate models backed by verified fallbacks; more accurate by increasing the effective fidelity of the subscale models beyond what is currently feasible; and portable by providing a general framework applicable to a wide range of use cases.
AMS provides the end-to-end infrastructure to automate all steps in the process from training, testing, and deploying machine learning surrogate models in scientific applications. With simple code modifications, developers can integrate AMS into their scientific workflows. This enhanced workflow enables calculations that were previously almost impossible due to their high runtime costs. If the surrogate model is found to introduce uncontrollable errors, AMS simply falls back to executing the original fine-grain simulation itself, avoiding the introduction of such errors.
AMS can benefit many different types of multiphysics simulations. For example, AMS has been used by the National Ignition Facility to model radiation transport as well as the behavior of energetic materials such as TATB. The AMS team works closely with Livermore Computing to test and push the boundaries of classical high performance computing.
This work was prepared by LLNL and supported by the Laboratory Directed Research and Development Program under Project No. 22-SI-004.