
The high performance computing (HPC) world is full of complexity—from applications to the software components they rely on and the hardware they need to run. With the first three exascale machines, including Livermore’s El Capitan, slated to come online in the next few years, addressing complexity challenges will be a heavier, more urgent lift. Like our current Sierra system, these exascale systems will derive most of their computational power from secondary accelerator processors called graphics processing units (GPUs).
Traditionally, HPC systems have used only central processing units (CPUs). With these machines, developers will need to accommodate not just NVIDIA accelerators but also new offerings from AMD and Intel. Harnessing the power of these devices entails using rapidly evolving programming environments, which require new compilers, runtime libraries, and software packages whose relationships are not always well understood. Without automated approaches to integration, developers will fight these software stacks by hand—but manual integration and maintenance are unsustainable.
A new effort kicking off in fiscal year 2021 aims to develop a machine-verifiable model of package compatibility that will enable automated integration, reducing human labor and errors. Funded as an LDRD Strategic Initiative, the Binary Understanding and Integration Logic for Dependencies (BUILD) project will run for three years with computer scientist Todd Gamblin at the helm. He states, “This project will develop techniques that enable rapid integration of HPC software systems, especially for upcoming exascale machines.”
Huge Burden, High Cost
The Lab is home to some of the world’s most complicated codes, which push the limits of hardware and software in a quest to simulate physical phenomena, predict material behaviors, and more. Software necessarily changes over time, especially as computer architectures evolve, and changes introduce incompatibilities among the packages these codes rely on in order to run.
For example, the Lab’s proprietary HPC neural network code LBANN (the Livermore Big Artificial Neural Network Toolkit) relies on 70 external packages, with 188 dependency relationships among them. Cutting-edge codes are not frozen in time—indeed, many of these external packages are evolving rapidly, just like LBANN. To run LBANN, developers and users must have a compatible set of dependency packages installed. Identifying a compatible set of versions for these packages—along with build options, compilers, operating system updates, and other parameters—so that LBANN can run on the Sierra supercomputer is difficult. Preparing LBANN to deploy under different circumstances or on another machine is even more so. Gamblin points out, “Software isn’t fixed at one point in time.” Even when some aspects of an HPC ecosystem are stable, developers must adapt when other aspects change.
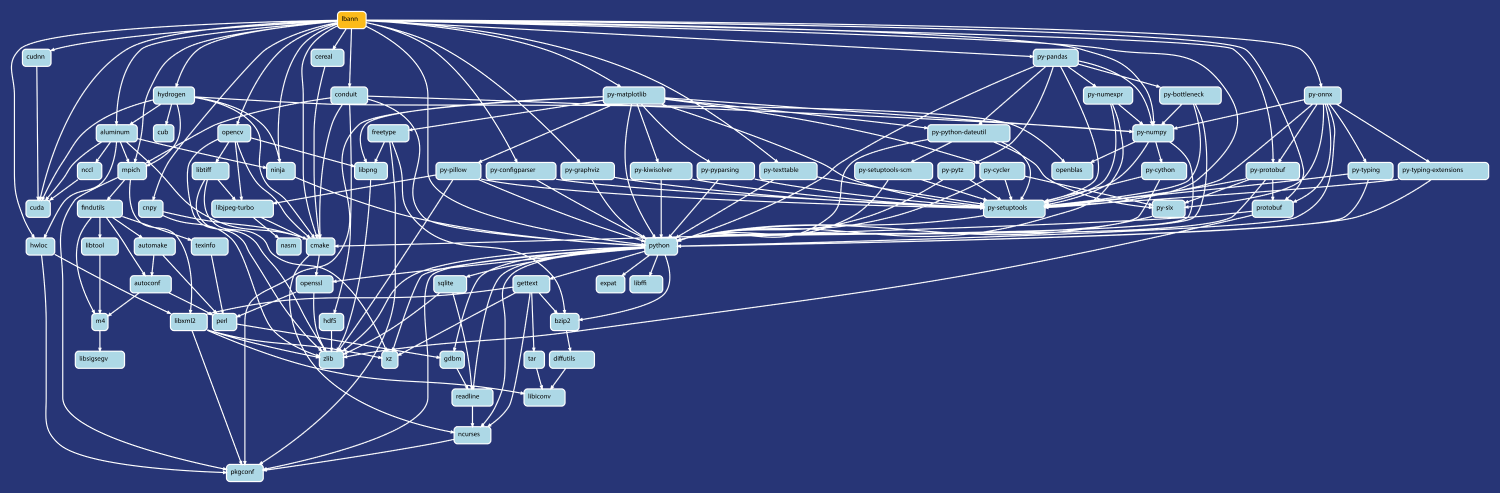
“Software integration is a huge burden, and combinatorial HPC builds will catch up to us,” Gamblin says. “We don’t control all the software we’re trying to integrate with.” For instance, LLNL’s ARES multiphysics code also relies on dozens of open-source packages. Additional challenges for code teams include integration with machine learning (ML), containers, or cloud workflows. Code teams can spend days or weeks troubleshooting dependency conflicts instead of running their applications, analyzing simulation data, developing new features, or making the most of computing resources.
State-of-the-art solutions are limited. Bundled distributions such as RedHat and SuSE include a set of mutually compatible dependencies, but they ensure stability by relying on old versions of software. Rarely is the distribution’s version of a package the same one needed by the Lab’s proprietary codes. Techniques like semantic versioning have become popular for expressing software compatibility, but they need humans to specify versions correctly, and many packages have not adopted this convention.
A third approach, favored by large corporations and called live at head, ensures stability by using extensive testing, but it requires all users to work with the latest version and the same configuration of all packages. The HPC community requires more flexibility than this approach allows, so the BUILD team seeks a better solution.
A Logic Puzzle
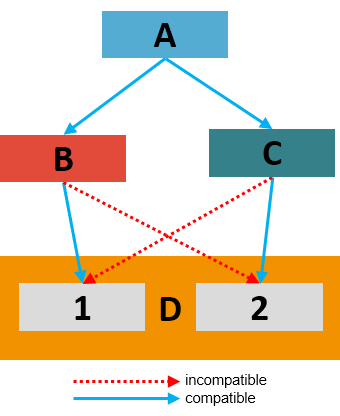
The compatibility problem is analogous to a jigsaw puzzle, where the pieces fit together in a certain way. When a new version of one piece is introduced, the tab on one side may change to a pocket, or vice versa, or multiple sides may change. Connections to that piece must be reexamined, then secondary connections, and so on until all dependencies are updated or confirmed to work. As software progresses in time, new or modified pieces cause more constraints on neighboring pieces. The decision process determines how pieces are affected—and which are unaffected—as changes propagate throughout the puzzle.
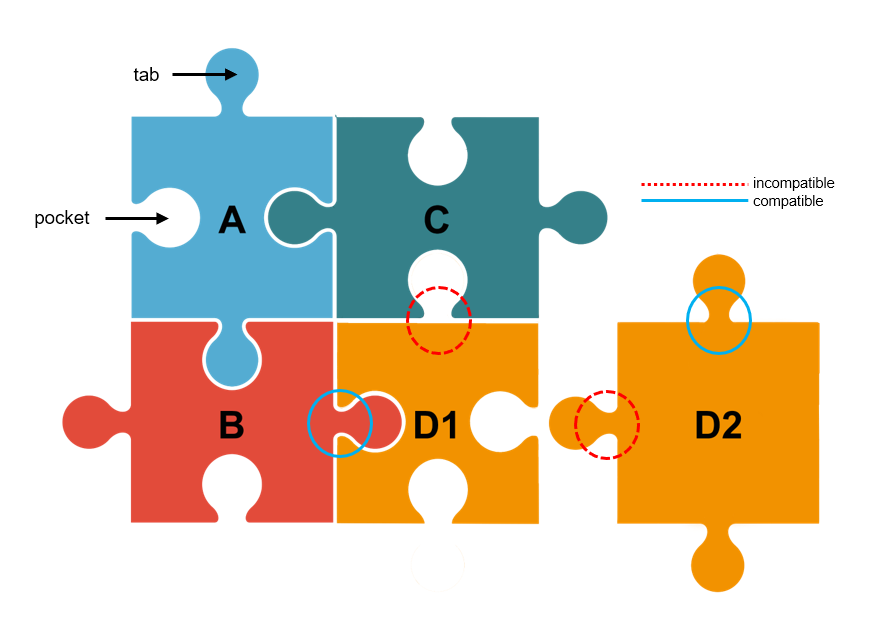
Given an arbitrary set of puzzle pieces, finding compatible configurations is a type of NP-hard problem, which means that, in the worst case, finding a solution will always require trying and checking every combination of puzzle pieces. (Read more about edge-matching puzzles.) Solvers for NP-hard problems have made great strides in the past two decades. Using algorithms like CDCL (conflict-driven cause learning), very large industrial problems can now be solved far more quickly than the worst-case scenario.
According to Gamblin, “The time is right to apply advanced solvers to the build configuration problem.” If an algorithm can find the optimal compatibility solution quickly, then developers can streamline and automate software integration. Solving software compatibility problems correctly and efficiently lies at the heart of the BUILD project.
Four-Pronged Approach
The project will build on Spack—the widely adopted package manager with a repository of more than 5,700 packages. Created by Gamblin in 2013 and today supported by a core development team, Spack already incorporates package configuration capabilities with dependency solving techniques.
The project team is seizing the opportunity to expand Spack’s capabilities beyond managing packages and their versions to considering how packages are built. A software library’s application binary interface (ABI) defines how the program interacts with other packages. Gamblin states, “Package managers currently consider very little about ABI, but it provides us with ground truth about compatibility. Focusing on ABI will give us a deeper understanding of library compatibility, and may enable us to auto-generate many of the constraints that are currently encoded manually using software versioning.”
Accordingly, BUILD’s four integrated research and development thrusts confront these questions: What makes software packages compatible? How can compatibility be assessed automatically? How can valid configurations be discovered, and, among those, what are the optimal configurations?
The first thrust will focus on dependency compatibility models with a goal of producing formal specifications for ABI (data types and functions) and other properties (such as compiler and GPU runtime libraries) that affect software package compatibility. This effort will also develop a software library of integration test cases. These models will demonstrate how incompatibilities develop over time and constrain how packages can be used together.
Another thrust aims to develop binary analysis tools that automatically discover a software library’s ABI to check compatibility with existing code. This practical application of the first thrust will use ABI-extraction techniques to generate compatibility models from arbitrary binaries (i.e., executable programs). This type of analysis will enable developers to know in advance whether particular versions, builds, or configurations of specific packages will be compatible.
BUILD’s third thrust will investigate efficient logic solvers that can determine valid software configurations based on packages’ full ABI compatibility information. Rather than relying on human-annotated metadata (e.g., package version), this effort will find known compatible configurations before developers try to build them. These solvers will be tested on Spack’s large package repository.
The fourth thrust will explore optimization techniques using ML to predict high-quality software configurations based on performance and correctness criteria. For example, a new model could predict whether a given configuration will likely perform well or fail testing. The ML models will train on Spack’s package repository, learn from past versions, and be integrated into the logic solvers.
Significant Benefits
Cumulatively, BUILD’s four thrusts lay the foundation for integrated software analysis and could enable much more sophisticated dependency management for many software ecosystems. The team estimates that build and deployment workflows could accelerate by 10–100x, as this approach would allow developers in many cases to reuse existing binaries and avoid building software. Such results would greatly benefit the Lab’s participation in the Advanced Simulation and Computing Program and Exascale Computing Project as well as impact the broader HPC and scientific communities.
Other software ecosystems, like Python and major Linux distributions, have struggled to integrate lower level binary packages not built in very prescriptive ways. Leveraging the techniques developed in BUILD, they could improve their ability to interoperate with lower level libraries and other programming languages.
Reducing the software dependency management barrier on new hardware architectures means that porting code to new machines will be easier, and maintenance (e.g., after an operating system update) will be conducted more quickly. “Our project’s multi-year design dovetails with the delivery of El Capitan and other exascale systems in the Department of Energy complex,” Gamblin points out.
The project will promote the reuse of software across teams and use cases. “Developers tend to standardize a core set of configurations in their ecosystem, so they must manually manage changes and rework their software stack for upgrades,” Gamblin explains. “In our new paradigm, where software can be much more easily reused, they wouldn’t have to do that as much.” Enabling rapid development of HPC software means meeting deliverables more quickly.
The BUILD team also intends to influence software development best practices, publishing their techniques and results through various channels. Many of the project’s tools, methods, solvers, and algorithms will be built into Spack and, therefore, available as open source. Another benefit is that Spack will become faster and easier to use.
Formidable Resources
BUILD is funded by the Laboratory Directed Research and Development (LDRD) Program—a competitive program that invests in innovative projects and new research directions at the Lab. Specifically, BUILD is one of the Program’s Strategic Initiative (SI) projects, which are large in scope and address key science, technology, and engineering challenges that align with the Lab’s strategic planning.
Gamblin states, “Funding at the SI level allows us to identify deep research problems that will impact programs and users. Our project combines a technical nuts-and-bolts production angle with fundamental questions about software.”
Like other ambitious Livermore projects, a multidisciplinary team will be key to BUILD’s success. Thrust areas will be led by computer scientists from the Lab’s Center for Applied Scientific Computing (CASC) and Livermore Computing (LC) Divisions, with application liaisons in the Global Security Computing Applications Division and the Applications, Simulation, and Quality Division. Additional software development and postdoctoral research staff as well as academic partners round out the team.
Many of the Lab’s mission-driven applications—such as multiphysics and hydrodynamics simulation codes—will benefit from automated software integration on both existing and future HPC systems, so liaisons from these areas will be on hand to test new capability prototypes. BUILD will leverage a range of LC’s HPC systems such as Linux commodity clusters and the Lassen supercomputer.