
Lawrence Livermore’s supercomputers are some of the most capable in the world, providing close to 100,000 compute nodes spread across nearly two dozen systems to calculate the intricate mathematics that underpin key scientific problems. As the demand for higher fidelity, multiscale scientific simulations increases and computational workflows become more complex, advanced tools are needed to optimize the Laboratory’s architecturally diverse high performance computing (HPC) resources.
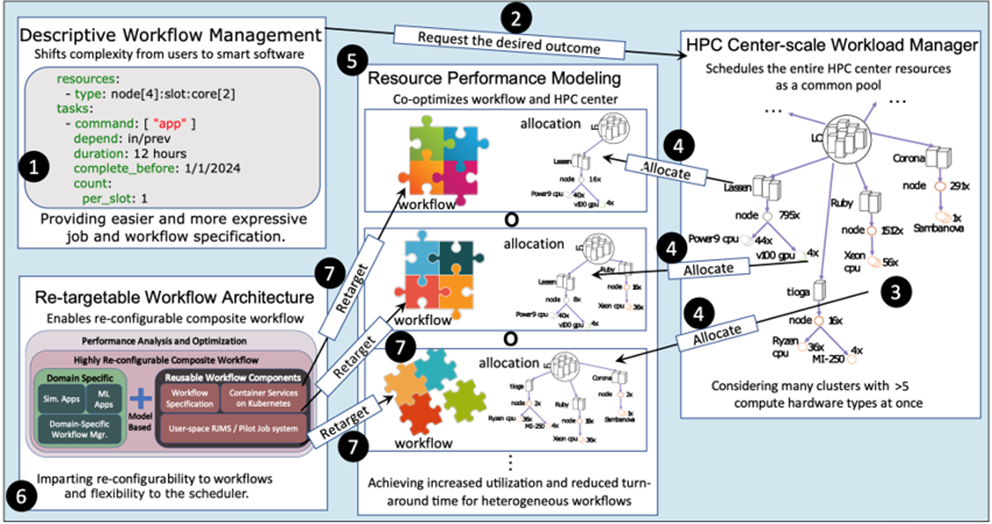
Harnessing the power of these machines to maximize utility and minimize waste is the basis of the Laboratory’s FRACTALE (Fractal Resource Allocation for Center-wide Throughput Acceleration Leveraging Elasticity) project. Funded through a Laboratory Directed Research and Development (LDRD) Program strategic initiative (SI), FRACTALE aims to improve resource management by delivering a center-scale programming and resource-allocation paradigm that automates workflow execution across heterogeneous HPC resources—shifting the burden of planning and resource matching from the user to the system.
Tom Scogland, the principal investigator for the LDRD project, says, “A center-scale programming paradigm that reasons about the user’s goals and application rather than specific center and system details is far simpler than today’s explicit imperative model, where users must specify exactly what the system needs to do. FRACTALE will improve the way scientific workflows use HPC resources and enhance the efficiency of the entire HPC center—reducing the user’s time to scientific discovery.”
Center-Scale Automation
The ability to extract the most scientific data from the compute power expended relies on an intricate dance of component tasks, from data storage and file transfer to data processing and visualization. Depending on workload requirements and dependencies, some types of hardware work better than others for executing specific actions. Traditionally, users must undertake the tedious job of manually selecting how each step of a workflow maps to specific machines, hardware types, and system settings. Alternatively, FRACTALE will incorporate intelligent software that automatically chooses the best available computing resources across the entire HPC system pool based on simple user descriptions of desired outcomes.
FRACTALE is a graph-based, hierarchical framework—wherein computing resources are represented as connected objects organized in layers from large groups (center) down to smaller parts (nodes). Built upon an enhanced version of the Laboratory’s R&D 100 Award–winning Flux software, FRACTALE will manage nested tasks and subworkflows across Flux instances.
Over the course of the three-year LDRD SI, the FRACTALE team will integrate four thrust areas into a single integrated approach. The four thrusts include: evaluating modeling methods to transform generic resource requests, such as tasks involved, dependencies between tasks, and cost and time limits, into a low-level native form for center-scale execution; designing novel software so that workflows can be described flexibly and easily adapted to different hardware; optimizing performance across the entire computing center using heuristics to find nearly optimal solutions for the center’s aggregate performance; and finally, leveraging AI across all the thrust areas to improve planning and scheduling for next-generation workflows.
Practical Application with MuMMI
The FRACTALE development team used the Multiscale Machine-learned Modeling Infrastructure (MuMMI) application as a benchmark for utility and performance. MuMMI is a high-complexity, domain-specific workflow codeveloped with Flux/FRACTALE that incorporates multiple length and time scales to model the interactions of oncogenic membrane proteins (RAS-RAF). Flux enables MuMMI to run 100,000 simulations at scale from the continuum (zoomed out lipid bilayer) to the course-grain (zoomed in view of protein–lipid interactions) to the molecular interactions between proteins and lipids at the atomic scale. Scogland says, “There wouldn’t be enough RAM (random access memory) in all the nodes onsite to do this type of work if it were run in the traditional way as one big monolithic code.”
Instead, MuMMI uses a multilevel refinement approach in which fine-grain models are dynamically generated from the coarser grain models based on certain parameters. Uniquely, the fine-scale simulations are then used to update and improve the coarser-grain simulations while the entire multiscale campaign is running, which means relevant processes can be captured at different levels of granularity. “It’s becoming more frequent that we get workflows where to do what the scientists want to do, we have to run approximately 15,000 different components, with four or five of them having completely different requirements,” says Scogland. “Co-design between MuMMI and Flux helps us identify potential features and multicluster submissions for running independent simulations. With the overall progress made with MuMMI (now a fully open-source code), FRACTALE integrations are on schedule.”
Delivering an Optimized Computing Solution
As the third year of the LDRD effort comes to an end, the team are engaged in advancing each of the thrust areas. The team has released more than 20 workloads for testing on various hardware to develop and characterize performance modeling techniques at the center level, and they continue to integrate AI to further improve performance and progress toward achieving their ultimate objective. “The goal of the FRACTALE project is to get the scientific answers to users as efficiently as possible, enable the center to make the best use of its expensive heterogeneous resources by minimizing waste, and boost user productivity by improving the programmability and expressiveness of jobs and workflow,” says Scogland. “At the end of the day, FRACTALE will help us get more science done on all the resources that we spend so much time, effort, and money bringing in.”
—Caryn Meissner