
To satisfy the increasing demands of scientific applications, supercomputers continue to grow in scale and complexity. Each new system introduces unfamiliar computing architecture that can take users days, weeks, or even months to efficiently accommodate different types of memory, processors, and other heterogeneous hardware. Furthermore, many applications need to run on different machines hosted at different computing centers, making the mapping of applications to the hardware a key factor in the productivity of high performance computing (HPC) application developers.
To utilize these modern heterogeneous systems, scientists must compose their applications using a combination of programming abstractions and runtime systems. For every compute abstraction in an application (e.g., process, thread, kernel), mapping an application entails selecting an appropriate hardware resource to execute every instance of that abstraction. The mapping burden compounds with each supercomputer the application needs to use. This challenging scenario drastically increases users’ time, costs, and expertise necessary for running their HPC applications.
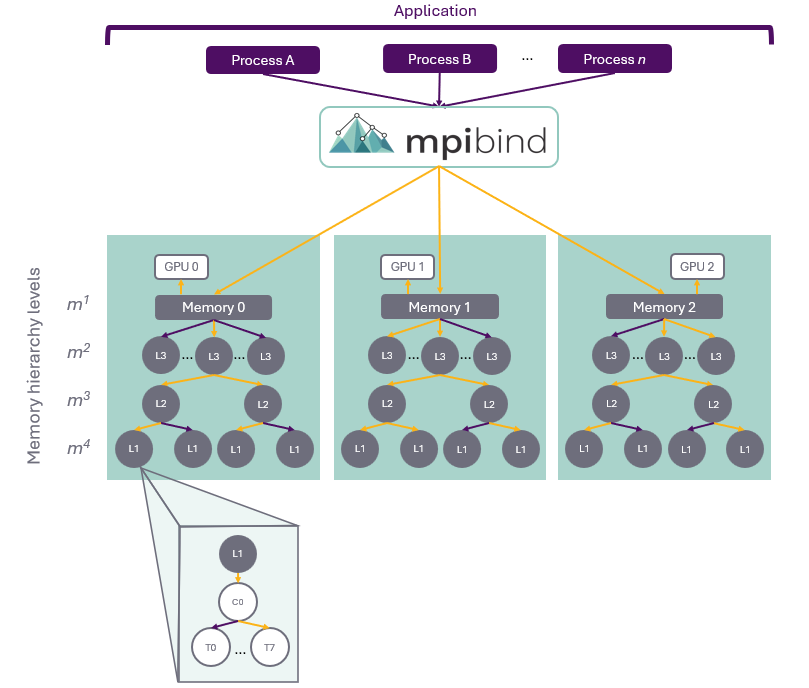
The mpibind (M-P-I-bind) software library automatically maps HPC science applications to supercomputers, relieving users from understanding any given machine’s architecture and its complex hardware topology. mpibind automatically discovers the machine’s unique topology and, using the locality (near proximity) of compute and memory devices, assigns these resources to each of the application’s abstractions.
Memory Hierarchy and Resource Locality
The key to mpibind’s algorithm can be stated simply as follow the memory hierarchy. Compute units are abundant on HPC systems, but memory capabilities do not provide equal solvency. As a result, application performance is limited by memory capacity, memory latency, or memory bandwidth. However, resource managers and MPI libraries in charge of mapping applications have primarily focused on the compute resources. This is where mpibind is different: Since its inception, mpibind’s design has centered on mapping applications to the memory system first and then assigning compute resources associated with the given memory components.
mpibind’s algorithm is portable across computing systems; it can be applied to any heterogeneous machine as long as mpibind is able to discover the architecture’s topology, which is necessary to build the machine’s memory tree and to assign compute resources to the memory vertices. Because the compute assignments to the memory vertices follow the architecture’s topology, mpibind’s mappings leverage the improved performance of using local resources like local memory and local GPUs.
Productivity, Portability, and Performance
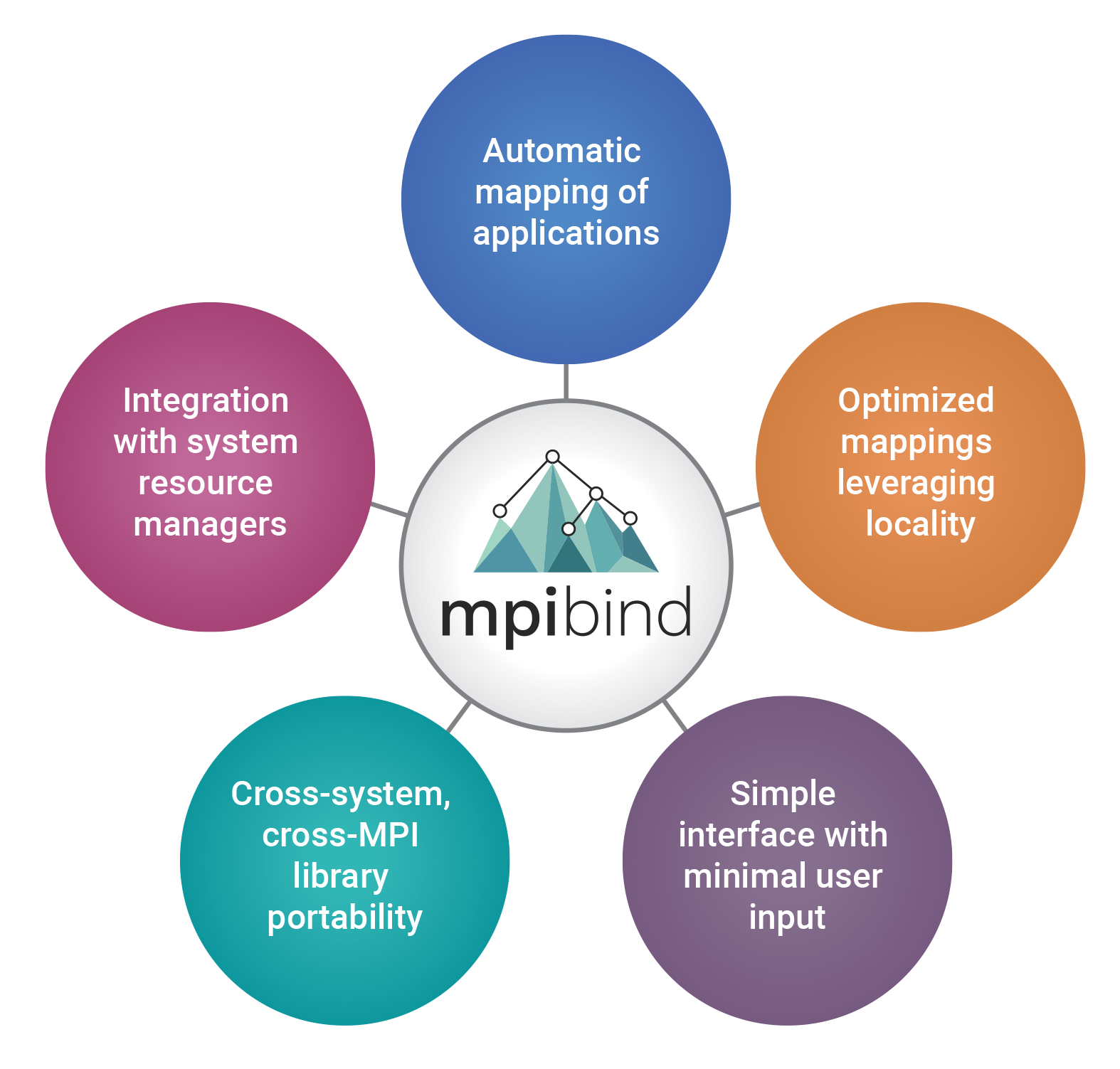
mpibind provides important features for productivity, portability, and performance:
- automatically maps HPC applications to heterogeneous hardware
- provides a simple interface with minimal user input
- is integrated with HPC resource managers
- leverages local GPUs and memory resources
- provides portability across HPC systems
- is production ready and open source
Citations
Edgar A. León, et al. TOSS-2020: A Commodity Software Stack for HPC. In: International Conference for High Performance Computing, Networking, Storage and Analysis. SC’20. IEEE Computer Society, Nov. 2020, pp. 553–567. doi: 10.1109/SC41405.2020.00044.
Edgar A. León and Matthieu Hautreux. Achieving Transparency Mapping Parallel Applications: A Memory Hierarchy Affair. In: International Symposium on Memory Systems. MEMSYS’18. Washington, DC: ACM, Oct. 2018.
Edgar A. León. mpibind: A Memory-Centric Affinity Algorithm for Hybrid Applications. In: International Symposium on Memory Systems. MEMSYS’17. Washington, DC: ACM, Oct. 2017.