
Non-deterministic software bugs are one of the most time-consuming and expensive problems to solve in software development. Tedious to find and often detected late in development, non-deterministic errors occur only occasionally and sporadically, even when run with the same input on the same hardware. These productivity killers are remarkably challenging to catch due, in large part, to being difficult to reproduce. Some errors do not reproduce even when being debugged, as the act of debugging may perturb the execution enough to mask the bug.
Unfortunately, non-deterministic debugging of parallel applications running on large supercomputers, such as those at Lawrence Livermore, presents even greater challenges. Supercomputers may contain millions of compute cores, and applications running on such systems must rely on multiple communication and synchronization mechanisms as well as compiler optimization options to effectively utilize the hardware resources. To find and fix non-deterministic errors in this complex environment requires significant effort and machine time.
A recent case study at Livermore indicated that resolving a single non-deterministic bug can require 3 months of programmer effort and 19 years of compute-core time—time that takes away from the science the user is trying to conduct. Thus, tools that can detect and remedy these defects are highly valuable. In collaboration with the University of Utah and RWTH Aachen University, Livermore researchers have developed PRUNERS, the only software toolset designed specifically to solve the challenges of debugging and testing for non-deterministic software bugs with the scalability, accuracy, composability, and portability demanded by today’s largest systems and applications.
The PRUNERS Toolset offers four novel debugging and testing tools to assist programmers with detecting, remediating, and preventing these errors in a coordinated manner. The core objective of these tools is effectiveness in scalably detecting, controlling, and testing targeted, system-software-introduced sources of non-determinism.
The toolset specifically aims at the non-determinism introduced by using today’s most dominant parallel programming models, the Message Passing Interface (MPI) and the OpenMP shared-memory programming application programming interface (API), as well as major compilers. The development and source code of these programming models and compilers are outside the control of the programmers. Therefore, a non-deterministic error caused by their use is extremely difficult to diagnose without proper tools. This is sharply contrasted with application-level sources where programmers have explicit control over the application and visibility into the source code.
The PRUNERS Toolset comprises four interoperable individual tool components:
- ARCHER for scalable and accurate OpenMP data-race detection (a data race occurs when two or more threads can access shared data without proper synchronization);
- ReMPI for scalable record-and-replay of MPI message exchanges;
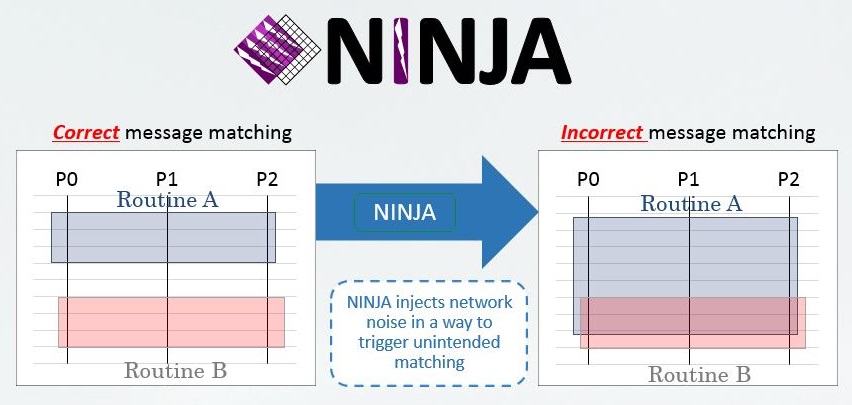
- NINJA, a smart noise injector for quickly exposing unintended MPI message races; and
- FLiT, a test framework for revealing compiler-induced floating-point variability.
To ensure high agility and applicability, each individual component works effectively as a single, standalone tool. In addition, the components are designed to complement each other and to be seamlessly integrated into the existing debugging and testing ecosystem. In fact, one of the main design philosophies of PRUNERS is to provide effective non-determinism coverage for the existing state-of-the-art code-development environment on supercomputers.
PRUNERS introduces this coverage into the context of existing debugging and testing workflows. On a hybrid code that combines MPI and OpenMP, programmers can first use ARCHER to detect whether an OpenMP data race is responsible for the latent bug. With minimal changes to the build-and-test system, ARCHER can accurately and scalably analyze deficient conditions in which multiple OpenMP threads access shared data without proper synchronization.
If its analysis indicates that a data race is less likely the root cause, programmers proceed with the MPI-level tools of PRUNERS. Specifically, NINJA can quickly expose unsafe MPI message race conditions in which two or more “MPI sends” race to match with an “MPI receive” and at least one of them is unintended. Using ReMPI, programmers can record one occurrence of this intermittently occurring anomalous condition and subsequently replay it for further root-cause analysis.
Finally, FLiT offers a quick Litmus-like testing method to check if the application suffers from numerical result variability caused by a specific compiler and present compiler optimization options. Result variability can also depend on the platform on which the code is ported and run.


To ensure that the capabilities work for large application development, the PRUNERS team has engaged several production code-development teams at the Laboratory and tested the utility of the component tools on large code bases. “These users have challenged our research team with the bugs they previously deemed intractable,” says lead researcher Dong Ahn. “PRUNERS has consistently proven to be effective on them.”
Ahn cites an example in which ARCHER detected and helped fix highly elusive OpenMP data races in HYDRA, a massive multiphysics application for Livermore’s National Ignition Facility. The bug caused code crashes that only intermittently manifested themselves after varying numbers of time steps and only at large scales (8,192 MPI processes or higher).
Further, as Livermore code teams increasingly multi-thread their applications, they are integrating ARCHER directly into their build-and-test systems to catch data-race bugs at testing time, before production runs are conducted.
ReMPI has helped ParaDiS (dislocation dynamics application) and Mercury (domain-decomposed particle transport application) code-development teams debug and test MPI non-determinism. NINJA was shown to reproduce unsafe message races consistently within Livermore Diablo’s (massively parallel implicit finite element application) use of hypre (scalable linear solvers and multigrid method library), which had not been repaired in its 14-year history.

These early adoption successes indicate that the PRUNERS Toolset successfully offers the requisite scalability, accuracy, and composability to help debug and test for non-deterministic bugs with features and attributes commensurate with the world’s largest supercomputers. Livermore has already experienced cost savings from implementing PRUNERS. With its 2017 open-source release and potential widespread adoption, PRUNERS is expected to have a dramatic impact on the high performance computing community.