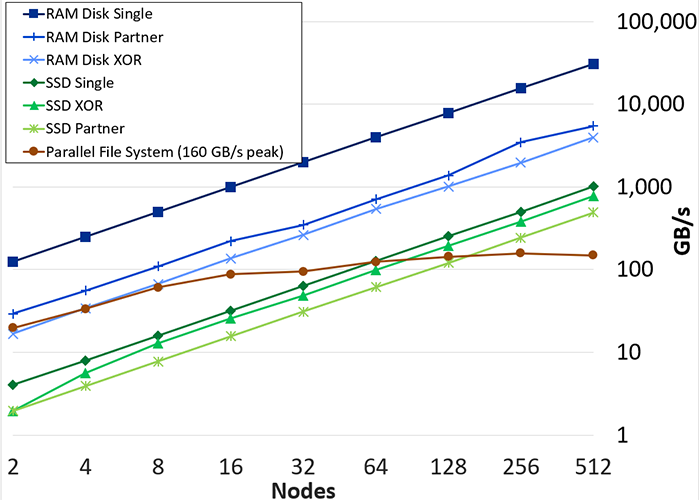
As HPC systems increase in size, checkpointing to the PFS becomes prohibitively expensive. Multilevel checkpointing may solve this challenge through lightweight checkpoints that handle the most common failures and relying on PFS checkpoints only for less common, but more severe, failures. To evaluate this approach in a large-scale production system context, the SCR library checkpoints to storage on the compute nodes in addition to the PFS. Through experiments and modeling, we show that multilevel checkpointing benefits existing systems, and we find that the benefits increase on larger systems. In particular, we developed low-cost checkpoint schemes that are 100x to 1000x faster than the PFS and effective against 85% of our system failures. Our approach improves machine efficiency by up to 35% while reducing the load on the PFS by a factor of 2.