Large-scale supercomputer simulations—often containing millions of lines of code—rely on hundreds of external software libraries, or packages. Users of the same high performance computing (HPC) system frequently need different versions and configurations of these packages to test the performance and compatibility of their code. Efficient packaging tools are critical in HPC environments, but traditional package managers are limiting because they cannot manage simultaneous installations of multiple versions and configurations. Consequently, users, developers, and HPC support staff spend many hours building codes and libraries by hand.
After many hours building software on LLNL’s supercomputers, in 2013 Todd Gamblin created the first prototype of a package manager he named Spack (Supercomputer PACKage manager). The tool caught on, and development became a grassroots effort as colleagues began to use the tool. The Spack team at Livermore now includes computer scientists Gregory Becker, Peter Scheibel, Tamara Dahlgren, Gregory Lee, and Matthew LeGendre. The core development team also includes Adam Stewart from University of Illinois Urbana-Champaign; Massimiliano Culpo from Sylabs; and Scott Wittenburg, Zack Galbreath, and Omar Padron from Kitware.
In 2019, Spack won an R&D 100 award in the Software/Services category and was an R&D Special Recognition medalist in the Market Disruptor—Services category. Since then, both the code base and open-source community have grown.
How Spack Works
Spack is now a flexible, configurable, Python-based HPC package manager, automating the installation and fine-tuning of simulations and libraries. It operates on a wide variety of HPC platforms and enables users to build many code configurations. Software installed by Spack runs correctly regardless of environment, and file management is streamlined. Unlike typical package managers, Spack can install many variants of the same build using different compilers, options, and message passing interface (MPI) implementations.
Moreover, writing package recipes for Spack is very simple. A single file contains a templated recipe for different builds of the same package, and recipe authors can differentiate between versions using a custom specification language developed by Gamblin. Behind the scenes, Spack handles the complexity of connecting each software package with a consistent set of dependencies. Each software’s dependency graph—showing the packages it relies on to function—is a unique configuration, and Spack installs each of those configurations in a unique directory, enabling configurations of the same package to run on the same machine. Spack uses RPATH linking so that each package knows where to find its dependencies.
By ensuring one configuration of each library per dependency graph, Spack guarantees that the interface between program modules (the application binary interface, or ABI) remains consistent. Users do not need to know dependency graph structure—only the dependency names. In addition, dependencies may be optional; concretization, a generalization technique, fills in missing configuration details when the user is not specific enough, based on user/site preferences.
Spack in Action
Various Livermore code teams are now making use of Spack. For instance, Spack was used to successfully automate software builds for ARES, a large radiation hydrodynamics code with more than 40 dependency libraries. At Livermore, ARES runs on commodity Linux clusters as well as petascale and exascale systems. Spack has reduced the time to deploy ARES on new machines from weeks to a few days. The ARES team can build many different versions of their code and pilot new configurations before deploying to production, allowing them to catch compiler incompatibilities and fix bugs before users are affected.
Open-Source Advantages
The development team realized early on that Spack’s usefulness extended beyond the Laboratory. Other HPC centers also spend considerable time deploying software, and application developers leverage the same open-source software, such as math libraries, graphical user interface toolkits, simulation frameworks, compilers, and MPI implementations. The challenge for HPC users is to tune the build for exotic HPC hardware. “It makes sense to share the cost of building and configuration across the community,” Gamblin says. “Spack allows developers to easily leverage the millions of lines of code that others have written.”
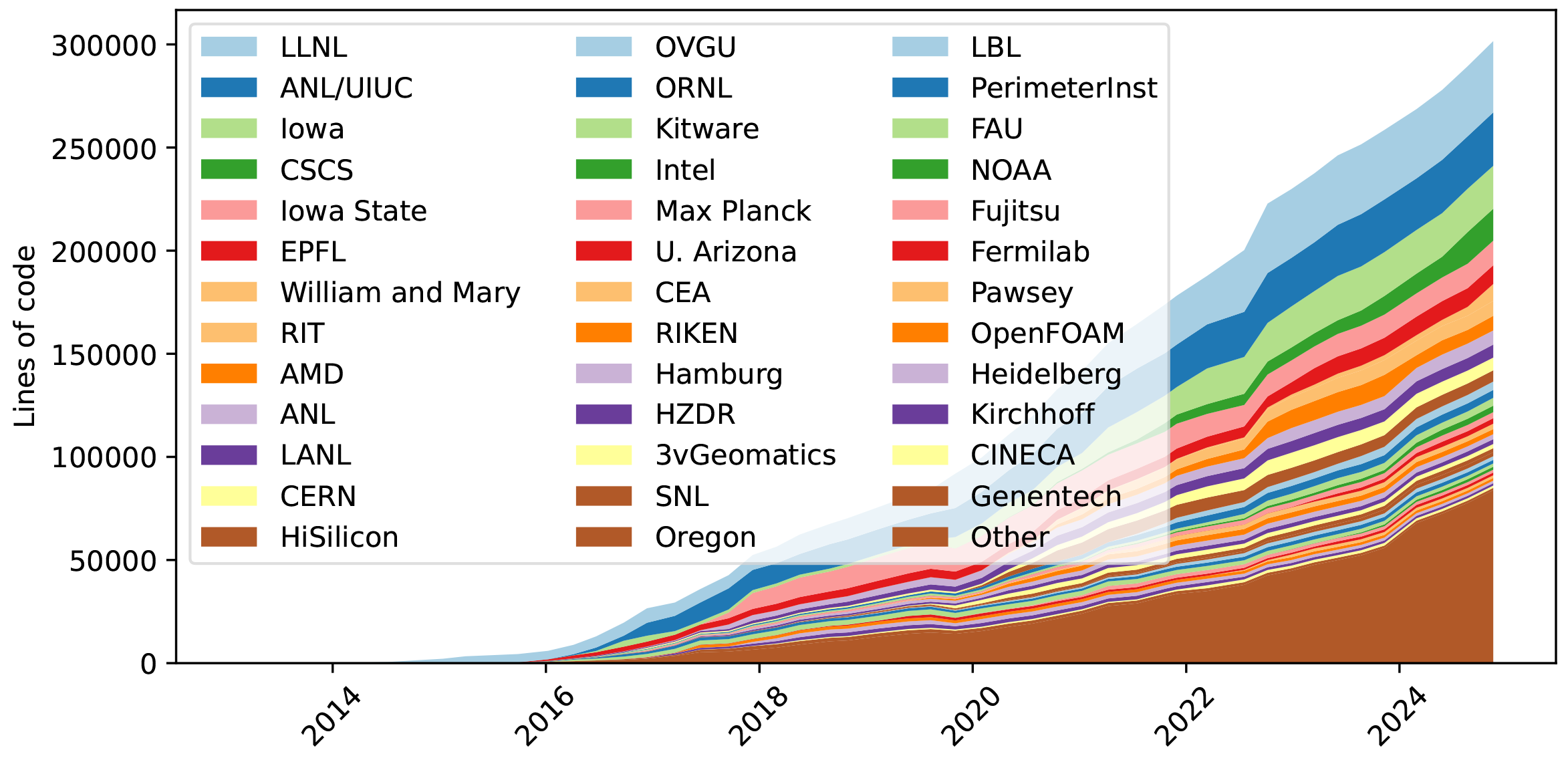
Spack was released as an open-source project in 2014, and Gamblin presented it at the Supercomputing 2015 conference. Outside collaborators began to contribute rapidly, growing the number of packages from 300 to more than 1,100 in just one year—and to nearly 8,500 overall. Today, three out of four Spack packages are contributed by outside institutions, both domestic and international. For each institution to maintain these packages separately would have been unsustainable; with Spack, each site benefits from the efforts of others.
The Spack team has leveraged this interest at subsequent Supercomputing conferences, where the Spack 101 tutorial and Birds of a Feather sessions are perennial favorites among attendees. Gamblin says, “Interacting with collaborators in person gives us a much better sense of the needs of the larger Spack community.” The tutorial is available as part of Spack’s documentation, and it has been presented by enthusiasts around the world as it gains traction at universities, research organizations, and other national laboratories.
Spack’s capabilities have expanded beyond Livermore’s machines to accommodate applications running on many different HPC architectures. Thanks to the Department of Energy’s (DOE) Exascale Computing Project, which ran from 2016 to 2024, Spack is used at the largest HPC centers in the DOE complex—including on all three of the DOE’s exascale supercomputers.
Efforts to support Spack as an open-source project have paid off many times over. Each month, the Spack team incorporates 100–150 changes from outside users. Frequently, the core team benefits from a long-desired feature submission or a solution to a problem already debugged by others. “We receive more contributions than we put in, which relieves the burden of building everything ourselves and allows us to build much more complex packages,” Gamblin explains. “Without the open-source community, we wouldn’t be able to sustain Spack.”
In 2024, the High Performance Software Foundation (HPSF) launched, co-founded by Gamblin and Kokkos lead developer Christian Trott of Sandia National Laboratories under the Linux Foundation banner. Through the foundation, DOE labs can work with academia and industry to advance a common, affordable software stack for HPC. Spack is a foundational part of this effort, with the first user-focused meeting held at the inaugural HPSF workshop in 2025.