
Disclaimer: This article is more than two years old. Developments in science and computing happen quickly, and more up-to-date resources on this topic may be available.
In This Issue:
- From the Director: 2017 External Review
- Lab Impact: Machine Learning for Arbitrary Lagrangian-Eulerian Simulations
- Collaborations: Using CFD Modeling to Advance Industry Low-Carbon Solutions for Iron Production
- Advancing the Discipline: SW4: Pushing the Boundaries of Seismic Modeling
- Path to Exascale: Reducing Data Motion Through In-line Floating Point Compression with zfp
- Highlights
From the CASC Director | Overview of Computation's 2017 External Review
Planning for the Computation Directorate's annual external review begins many months before the event. The preparations are important, first because we present our work to our external peers and to senior LLNL management. The process of planning also helps Computation leadership identify important trends and concerns. Although the general topic area is determined in advance, the specific questions we ask the committee to address evolve during planning. This year's review was also an opportunity for the Lab's new Associate Director for Computation, Bruce Hendrickson, to learn more about CASC's work.
Each year's review focuses on a different facet of Computation. This year the committee looked at research, so CASC was in the spotlight. Computation Directorate leadership asked the committee to:
- Assess the suitability of our scientific vision for computing at LLNL to meet the current and future needs of the Laboratory;
- Assess the impact of our research on the Laboratory’s national security missions;
- Assess the scientific and technical quality of our computational research;
- Assess the quality of our workforce and the state of our computational capabilities; and
- Assess whether our R&D strategies are appropriate for ensuring leadership in the face of a rapidly changing computational landscape.
Over two days, the committee heard talks and saw posters describing how we plan to build an exascale computer in partnership with industry and other DOE labs and how we can build large scientific applications that will perform well on a range of future architectures. We showed how machine learning technology can improve the robustness of complex simulations and help optimize the usage of our computer centers. We also looked toward future architectures, programming methods, and applications. (This summary of research topics is intentionally brief; more details appear in this newsletter and in future issues.) The committee also met with customers and employees to learn their views on the organization.
The day after the presentations, the committee gave us their preliminary summary and recommendations. Their findings began with praise for the work and the workforce:
- Our approach to enabling high performance simulations on current and future architectures is holistic, innovative, and bold.
- We are world leaders in developing and deploying high performance computing (HPC) platforms for the most demanding large-scale simulations.
- We are poised to become leaders in the application of artificial intelligence in HPC.
- Our workforce has an excellent range of expertise and is committed to the Lab's mission.
It was gratifying to hear that the committee believes Computation research is headed in the right direction. However, we also wanted advice, and they offered several valuable suggestions. These included:
- Formally articulating a long-term vision and strategy for the Directorate;
- Nurturing the quality and depth of Computation's research capabilities; and
- Maintaining a strong commitment to a diverse workforce.
We look forward to studying the committee's recommendations in their final report and developing plans to act on them. I also want to thank the many members of Computation's research and administrative staff who put in the hours for a successful review.
Contact: John May
Lab Impact | Machine Learning for Arbitrary Lagrangian-Eulerian Simulations
As HPC becomes ever more powerful, scientists are able to perform highly complex simulations that couple multiple physics at different scales. The price that comes with this capability is that the simulations become much more difficult to use. Among the main culprits causing this difficulty are simulation failures. A common example can be found in hydrodynamics simulations that utilize the Arbitrary Lagrangian-Eulerian (ALE) method, which requires users to adjust a set of parameters to control mesh motion during the simulation. Finding the right combination of parameters to adjust in order to avoid the failures and to complete the simulation is often a trial-and- error process that can be a significant pain point for users.
There is an urgent need to semi-automate this parameter adjustment process to reduce user burden and improve productivity. To address this need, we are developing novel predictive analytics for simulations and an in situ infrastructure for integration of analytics. Our goal is to predict simulation failures ahead of time and proactively avoid them as much as possible.
Predictive Analytics for Simulations
Our goal is to develop machine learning algorithms to predict conditions leading to simulation failures. We are investigating supervised learning to develop classifiers that can predict failures by using the simulation state as learning features.
In Situ Infrastructure for Integration
In support of this goal, we are developing an in situ infrastructure to integrate the predictive analytics with the running simulation in order to adjust the parameters dynamically. This infrastructure will include components for data collection and user interface.

Figure 1 provides a high-level overview of an infrastructure for integrating machine learning into HPC simulations. At the top level is the user interface, where Workflow Management interacts with the Simulation Run and the Visual Analytics interacts with the Machine Learning. At the middle level is the data collection, where the key component is the Feature Aggregator, which aggregates massive simulation data into learning features for training data. At the bottom level is the predictive analytics, where the Machine Learning generates Statistical Models that are then used for Inference Algorithm.
Currently, we are focusing on predicting mesh tangling failures, which is a much more common problem plaguing current ALE codes and is due to the material motion twisting the volumetric mesh elements into an un-computable geometry – something the mesh relaxation algorithm (or ALE technique) is meant to mitigate against. We are developing a supervised learning framework for predicting conditions leading to these failures. Our framework uses the Random Forest learning algorithm and can be integrated into production-quality ALE codes.
In a recent paper, we present a novel learning representation for ALE simulations, along with procedures for generating labeled data and training a predictive model. We present a set of experiments designed to analyze the predictability of failures in terms of the features, and evaluate the performance of our learning framework. Finally, we show how to incorporate the predictions into an actual relaxation strategy and demonstrate its usage on two well-known test problems.
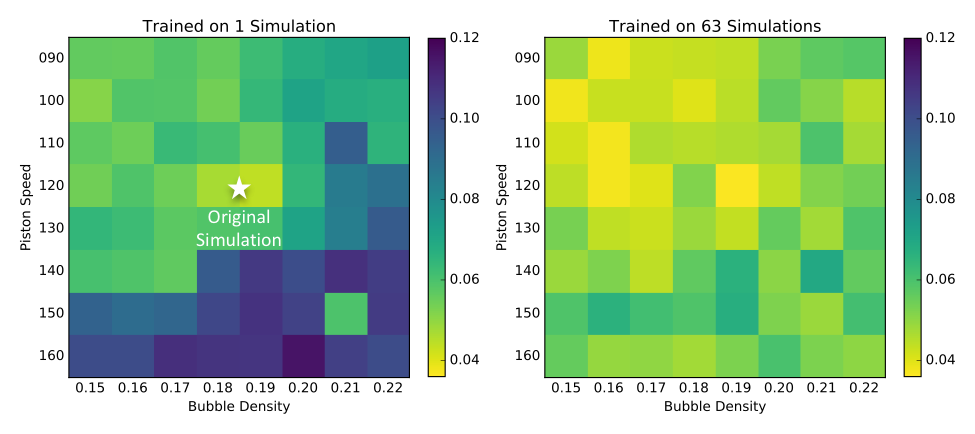
Figure 2 shows an example of applying machine learning algorithm to predict failures in ALE simulations. The color map corresponds to the root-mean-square error (RMSE) of the prediction made using a Random Forest model. The image on the left shows training on 1 simulation to predict failures in 64 other simulations; the image on the right shows training on multiple simulations via leave-one-out cross-validation. This illustrates, for the first time, that machine learning can be a viable approach to predict simulation failures when trained with sufficient number of examples.
Effectively setting ALE parameters in hydrodynamics codes has often been referred to by users as an “art form” versus a science. That sentiment points to exactly the types of algorithms we feel can be greatly helped by machine learning, and this work represents a promising early example of our goals to marry traditional simulation with artificial intelligence, with future efforts leveraging the infrastructure being developed in this effort.
Contact: Ming Jiang
Collaborations | Using CFD Modeling to Advance Industry Low-Carbon Solutions for Iron Production
The steel industry is the fourth largest energy consumer in the US. Most of that energy is consumed in blast furnaces utilizing coke (a derivative of coal) to smelt iron ore. Carbontec Energy Corporation has developed the E-Nugget process that utilizes biomass in place of coke in a linear furnace to produce iron. This process can be fed either iron ore or steel mill wastes pressed into briquettes with the biomass and a binder to produce high-quality iron nuggets suitable for steel production.
This work is supported by the Department of Energy's Efficiency and Renewable Energy Advanced Manufacturing Office (DOE/EERE/AMO) through the High-Performance Computing for Manufacturing (HPC4Mfg) program led by LLNL. Our team brings together computation experts here at LLNL with steel industry model experts at Purdue Northwest and the engineers at Carbontec to model the E-Nugget process and help Carbontec make decisions about bringing it to production scale.
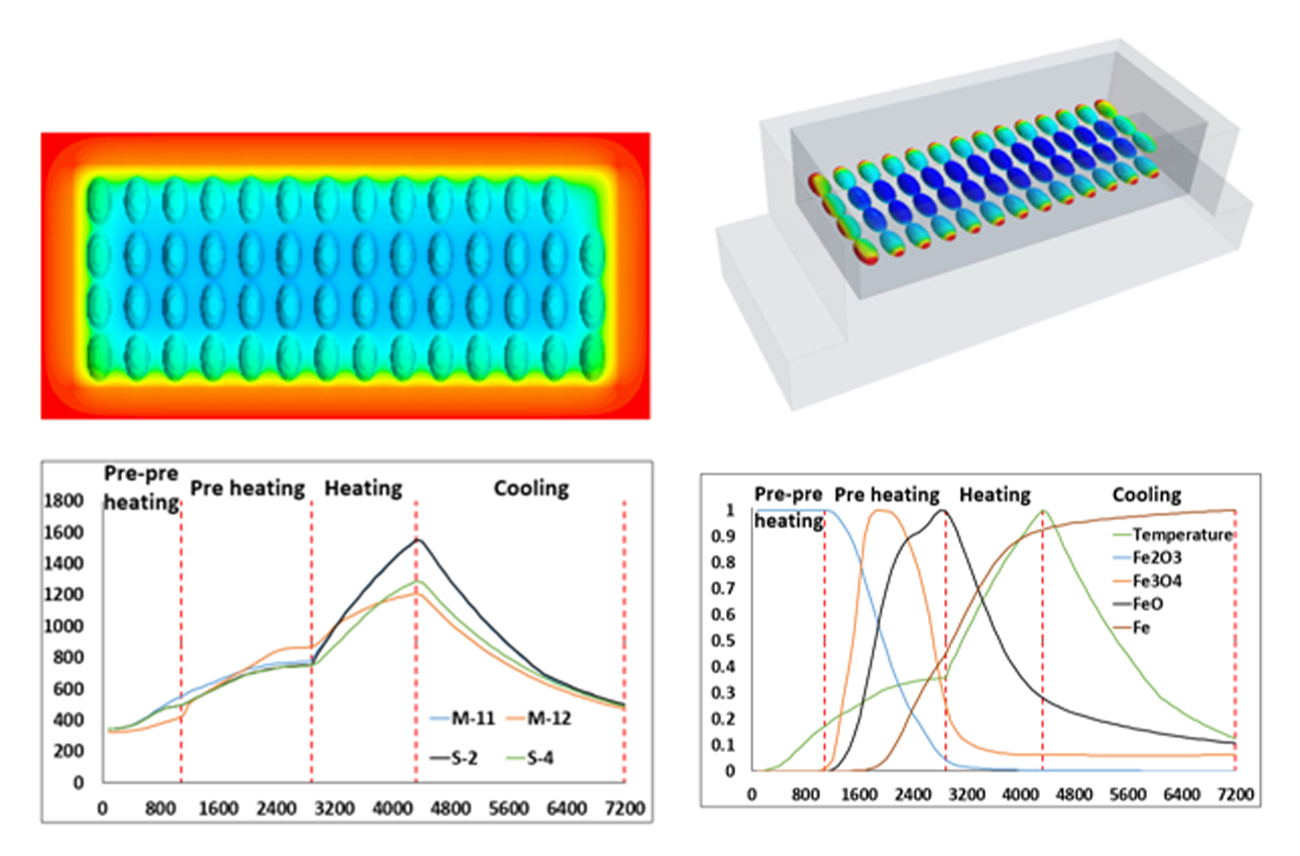
To begin, Carbontec shared data from their scale tests used to validate the core E-nugget process. The team utilized that data to build a Computational Fluid Dynamics (CFD) model of the process including the energy flow and the chemical reactions occurring in the nuggets as they heat up. Conditions for numerous experiments run in the pilot study were simulated allowing the team to tune and validate the model. The model allowed the team to identify the key temperatures that the nuggets need to reach to drive the chemical reactions to completion and drive the melting and coalescence of the iron into nuggets.
With this validated process model and understanding the team is now modeling a Carbontec design for a full-scale production furnace. We will use this model to examine the tradeoffs between building longer sections and turning up the temperatures in the furnace sections. This will help Carbontec make valuable decisions about their furnace design before spending the capital to build it. When complete, the first production-scale furnace will produce 200 million lbs/year of iron nuggets, which will eliminate 90 million lbs/year of coke consumption from normal blast furnace iron production.
Contact: Aaron Fisher
Advancing the Discipline | SW4: Pushing the Boundaries of Seismic Modeling
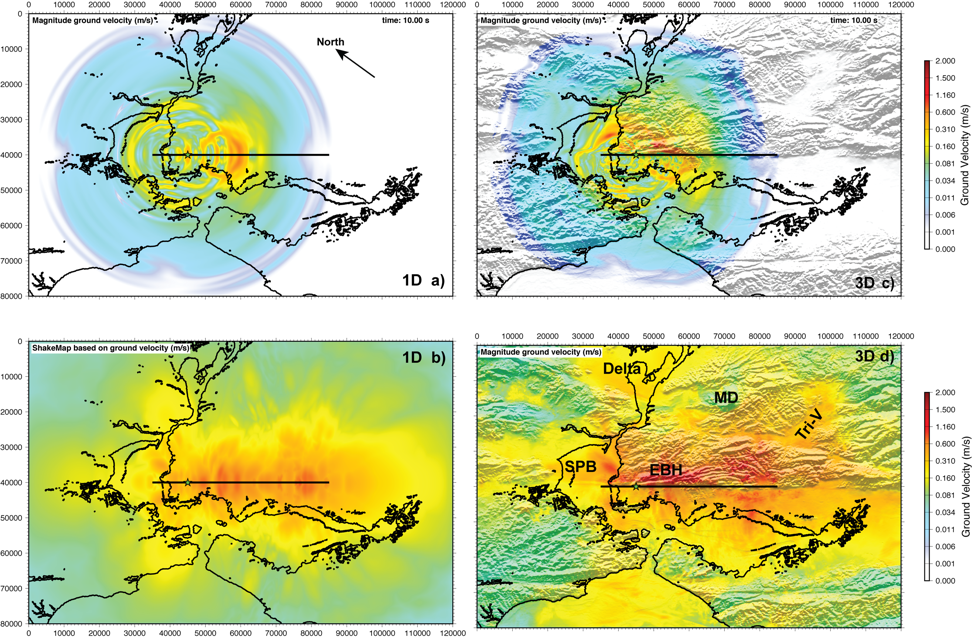
The holy grail for earthquake simulations is to capture the ground motion with such fidelity that structural damage or failure of buildings can be accurately predicted. For example, in the San Francisco Bay area, there is a high risk for significant damage to roads, bridges, dams, and buildings during the next rupture of the Hayward Fault, which could produce quakes of magnitude 7.0, or larger. By coupling high-fidelity seismic simulations with building dynamics simulations, we can now study the outcome of different earthquake scenarios from the safety of a supercomputer.
The fundamental challenge for earthquake modeling is to capture the ground motion at sufficiently high frequencies to be relevant to building dynamics, i.e., 5-10 Hz. Because the wavelength is halved every time the frequency is doubled, and a fixed number of grid points are needed per wavelength, the memory requirements in a seismic simulation scales as frequency cubed. Furthermore, the time step must be proportional to the grid size, which means that the computational complexity of a seismic simulation scales as frequency to the power of four. Hence, a 5-Hz simulation is 625 times more complex than a 1 Hz simulation, and it takes an additional factor of 16 in computational power to reach 10 Hz.
With the current version of our SW4 code, we can simulate motions with frequencies up to 2.5 Hz on a grid with 35 billion points using the Quartz machine (2100 nodes, 75,600 cores, for ~10 hours), see Figure 4. One way of increasing the frequency content is by adding compute power. In preparation for emerging and future machines, we are refactoring SW4 to use a hybrid MPI+X programming model. For many-core architectures such as Xeon Phi, our choice of “X” is OpenMP. Here a number of OpenMP-threads are spawned from each MPI-task. For mixed CPU/GPU architectures, such as Ray and the future Sierra machine at Livermore Computing, we are offloading the main computational tasks to the GPU. Here we are experimenting with implementations in both CUDA and RAJA.
Another approach for increasing the frequency content in seismic simulations is by improving the algorithm. Because the material velocities in the Earth increase with depth, significant amounts of computational resources can be saved by using a mesh where the grid size follows the velocity structure of the Earth. We recently implemented a 4th order, energy-stable, hanging-node, mesh refinement algorithm that allows the grid size to be doubled across each refinement interface. In realistic seismic simulations, this allows the number of grid points to be reduced by an order of magnitude. Or, alternatively, it allows the frequency content to be doubled using the same computational resources. Naturally, the full power of supercomputing will only be realized once the mesh refinement capability is efficiently implemented on many-core and mixed CPU/GPU architectures.
This work was supported in part by an Exascale Computing Project application project and by the LLNL Institutional Center of Excellence funding.
Contact: Anders Petersson
Path to Exascale | Reducing Data Motion Through In-line Floating Point Compression with zfp

One of the largest hurdles to clear on the path toward exascale computing is overcoming the problem of insufficient bandwidth available to move data around the computer's memory hierarchy to satisfy the voracious compute appetite of tomorrow's massively multicore computers. Without data arriving at a processor in a timely manner, there is nothing to compute on, leaving processors starved for work. Moreover, the need to synchronize the work in parallel computations often makes it difficult to overlap computation with communication and I/O, thus forcing processors to sit idly waiting for far slower I/O and message passing operations to complete—for example while writing simulation checkpoint files and results to disk.
In order to alleviate this data movement bottleneck, we are developing zfp, a new data compressor that reduces the size of numerical floating-point arrays and allows data to be transferred in less time by making it smaller. zfp performs data compression and decompression inline as data are being accessed while the application is running. It does so by partitioning arrays into small bite size chunks that are decompressed on demand for processing and are then automatically compressed and stored back in main memory when no longer needed.
zfp's C++ interface hides from the user the complexity of compression, decompression, and caching of uncompressed data, making zfp's compressed arrays appear and behave much like conventional uncompressed arrays. This facilitates adoption in existing applications by requiring only a small number of code changes, which require the user to specify how much compressed storage to allocate to each array. Although zfp must inevitably approximate the numerical values it stores when allocations are very small, its more economical representation allows it to exceed the accuracy of same-size uncompressed arrays by several orders of magnitude, providing, for instance, 50% savings in storage with no loss in accuracy.
zfp is a key component of LLNL's Variable Precision Computing project, where it serves as a mechanism for tuning the precision in numerical computations. zfp development is also being funded by the Exascale Computing Project. One of the goals of this project is to deploy zfp in common I/O libraries like HDF5 and ADIOS, as well as to apply it directly to data structures in key DOE science applications. As part of this effort, zfp has proven to deliver data reductions on the order of 100:1 for visualization, speedups of 10:1 in I/O operations, and 4:1 in-memory reduction of simulation state arrays with less than 0.1% error in quantities of interest. zfp has helped LLNL scientists transfer huge, peta-scale data sets across DOE sites that otherwise would be impossible.
As an example, zfp was recently used to compress billions of X-ray images produced by the National Ignition Facility's HYDRA code on Los Alamos National Laboratory's Trinity supercomputer, amounting to more data than the combined output of all prior runs in HYDRA's 20-year history. In situations like this, data compressors like zfp provide a solution to the unfortunate practice of having to discard the vast majority of data before it can be transferred and analyzed.
Contact: Peter Lindstrom
CASC Highlights
Looking back...

Fifteen years ago CASC welcomed 26 summer students. That was a large group at the time, but this year CASC is hosting nearly 100 students. Our summer program is an important part of CASC's identity, and it serves many purposes. First, the program introduces the students to the work we do at LLNL. This experience often helps to shape the students' research when they return to school, by focusing their work on important real-world problems. Second, the students can pursue ideas that staff members would not otherwise be able to fully explore on their own. The students also bring fresh ideas and perspectives. Third, the program helps CASC contribute to research communities by helping train the next generation of scientists. Some of those researchers eventually return and become CASC staff members themselves, including four from the summer of 2002: Timo Bremer, Aaron Fisher, Ming Jiang, and Tzanio Kolev.
Help us out!
If you're aware of a CASC project that you'd like to see highlighted in our next issue (coming out this fall), let us know.