
High performance computing (HPC) experts and users face a seemingly endless array of challenges in fully utilizing a heterogeneous system. While central processing units (CPUs) can handle general-purpose tasks, applications must take advantage of graphics processing units (GPUs) for compute-intensive tasks. To exploit the massively parallel processing this paradigm offers, an important research question is how to offload work from CPUs to GPUs to achieve the best performance.
“Everything not offloaded will become a bottleneck for the application. Offloading minimizes the end-to-end time to obtain a scientific result,” explains Johannes Doerfert, a computer science researcher in LLNL’s Center for Applied Scientific Computing.
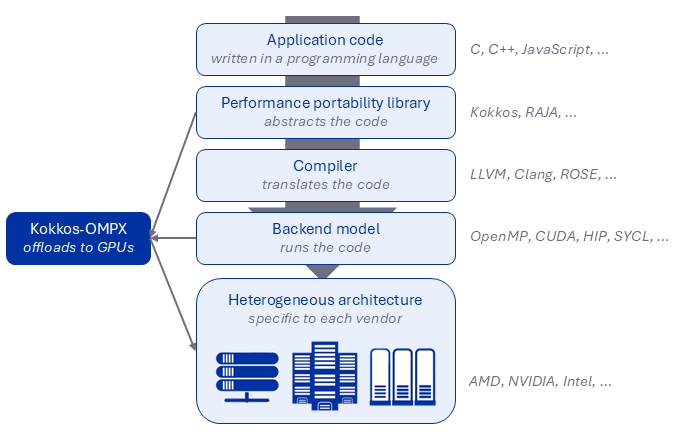
Hardware vendors have their own backend solutions using their preferred programming models. For example, the CUDA (Compute Unified Device Architecture) and HIP (Heterogeneous-computing Interface for Portability) models are respectively optimized for NVIDIA and AMD GPUs. But when an application needs to run on other vendors’ GPUs, developers must modify their algorithms governing parallel execution, data movement, memory access, and more. The larger the code base, the larger the effort.
New research suggests a more flexible, vendor-agnostic option for GPU offload: OpenMP. Eric Wright, who provides compiler technical support for Livermore Computing, points out, “In addition to improving application performance, we also need solutions that consider how developers actually use these tools and interact with these complex machines.”
Doerfert and Wright co-authored the paper “Leveraging LLVM OpenMP GPU Offload Optimizations for Kokkos Applications” alongside Rahulkumar Gayatri (Lawrence Berkeley National Laboratory), Shilei Tian (Stony Brook University), and Stephen Olivier (Sandia National Laboratories). The team won the Distinguished Paper Award at the 2024 IEEE International Conference on High Performance Computing, Data, and Analytics (HiPC) in December.
Coming Up to Par
Though globally recognized as a standard HPC backend, OpenMP doesn’t quite match the GPU-offloading capability of vendor-native models like CUDA and HIP. Its execution model has historically prioritized CPU parallelization, so it may seem an unlikely answer to the offloading question.
The name is a clue to its appeal: OpenMP is open. Managed by a consortium, OpenMP development transcends a single vendor’s preferences and processors. Doerfert says, “We investigated the performance features available in vendors’ backends that aren’t available in OpenMP, and where OpenMP uses costly workarounds to perform offloading.”
To bridge the gap between OpenMP and native backends, the team looked to another open standard: the LLVM compiler. In earlier work, the team introduced OpenMP extensions into LLVM that customize its capabilities for a range of HPC architectures. For instance, one extension offers dynamic shared memory allocation for OpenMP offloading, while another decreases runtime overhead for CUDA-style OpenMP target regions. LLVM has stable support for OpenMP on GPUs, and using these extensions in user code or abstraction layers can significantly improve offloading performance.
“Application developers struggle to understand which backend will give them the best results for whichever machine they’re using,” Doerfert notes. “Investing in OpenMP is risk mitigation for switching from one type of GPU to another. If something goes wrong in CUDA, for example, users can have an alternative solution. There doesn’t have to be a single point of failure.”
Cooking with Kokkos
A key ingredient in the team’s implementation is portability software—like the Kokkos and Livermore-led RAJA libraries—which provides abstraction layers to help applications run with different backends on different architectures. Kokkos is already compatible with several native backends including CUDA and HIP, but its OpenMP support falls short of effective hierarchical parallel performance and scalability.
This Kokkos-OMP framework and its GPU-offloading backend OpenMPTarget are the proving grounds for the team’s research. Integrating the LLVM extensions into Kokkos, their new model is called Kokkos-OMPX.
The team ran a molecular dynamics application on two types of GPUs: the petascale Perlmutter system’s NVIDIA processors at the National Energy Research Scientific Computing Center, and the exascale Frontier system’s AMD processors at Oak Ridge National Laboratory. The tests compared performance results for optimized sparse matrix vector (SPMV) computation using the Kokkos-OMPX solution versus CUDA and HIP.
A common algorithm in scientific applications, SPMV is nevertheless computationally expensive. “SPMV presents an interesting problem because it heavily benefits from the GPU’s unique parallel architecture. It’s a very good benchmark for GPU performance,” states Wright.
Kokkos-OMPX demonstrated consistently good performance on different architectures, and even better performance with a few additional SPMV optimizations (*-opt in Figure 2). Wright explains, “The optimizations from our extensions to OpenMP can significantly bridge the performance gap between Kokkos with OpenMP and Kokkos with CUDA or HIP.” Doerfert adds, “This proof of concept shows that you can extend OpenMP’s offload capability and still achieve on-par performance portability.”
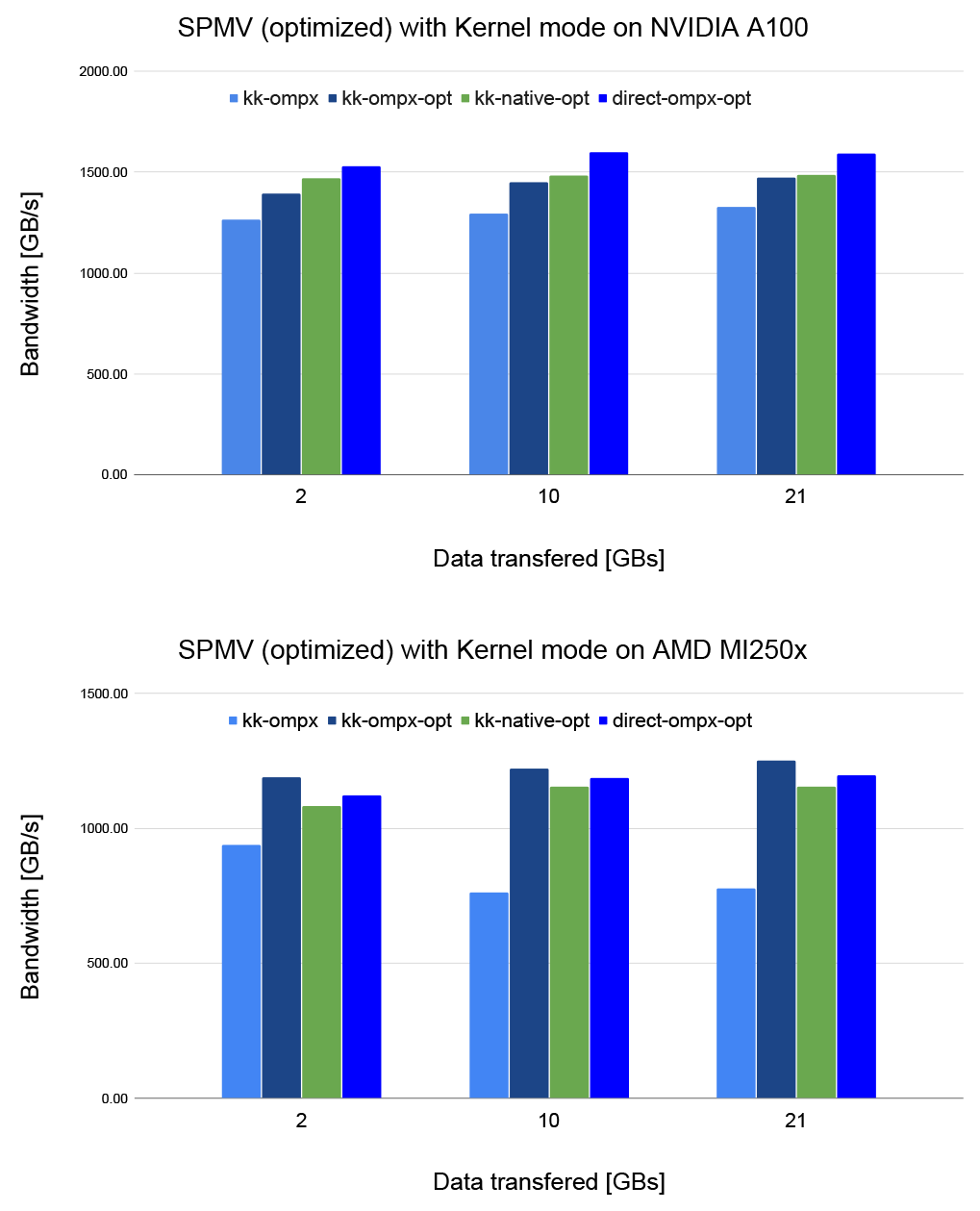
Since the conference, the team has been working with the OpenMP Language Committee to implement the extensions in the v6.1 release slated for fall 2026. “Using band-aid solutions is never good in the long run,” Wright cautions. “Introducing the extensions into the OpenMP standard makes it easier for developers to use and adopt, and its open nature means the HPC community can continue improving its performance without sacrificing user experience.”
Additional Livermore research was recognized at HiPC 2024. Hariharan Devarajan, Kathryn Mohror, and University of Maryland collaborators wrote “ML-Based Modeling to Predict I/O Performance on Different Storage Sub-Systems,” which was nominated for the Distinguished Paper Award. Another accepted paper was “HPC Application Parameter Autotuning on Edge Devices: A Bandit Learning Approach” by Tapasya Patki and co-authors from three universities.
—Holly Auten