
Large language models (LLMs) like GPT and Claude have shown incredible potential in a variety of software tasks, and most developers now rely on LLMs to increase their productivity. However, despite significant advancements, LLMs are far less effective at high performance computing (HPC) programming tasks. Models may lack sufficient HPC training data, contextual information, and nuances of parallel semantics or performance, while hallucinations and reasoning errors raise questions of reliability and trustworthiness. Accordingly, the emerging field of Code LLMs has produced benchmarks and made strides toward incorporating contextual cues into models.
A new project led by Center for Applied Scientific Computing (CASC) computer scientist Harshitha Menon, and funded as part of the Department of Energy’s (DOE) AI for Science Initiative, aims to advance the quality and use of Code LLMs in large-scale HPC applications. “Our goal is to revolutionize HPC software development and maintenance by enhancing the effectiveness of LLMs in this domain,” she says. The team is building LLM-powered agents that will assist HPC developers with complex tasks.
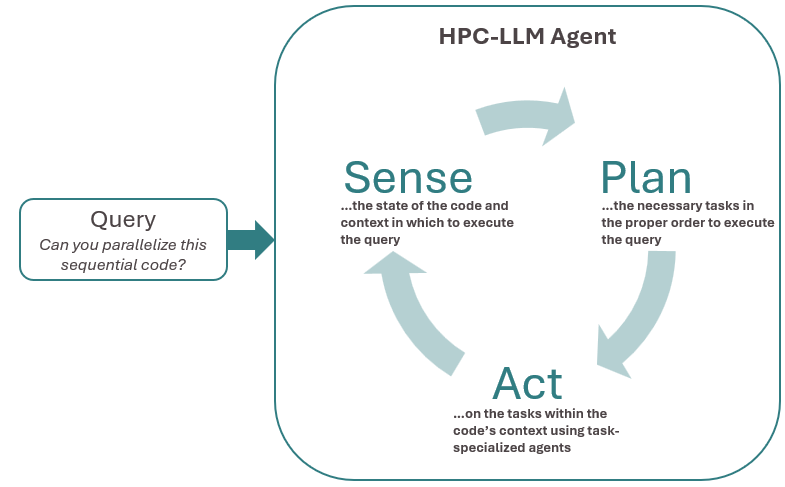
Sense-Plan-Act
Now a few months into the project timeline, HPC-LLM agents are already generating parallel codes to run on Livermore’s Tuolumne supercomputer and, eventually, El Capitan at LLNL and Frontier at Oak Ridge National Laboratory. As the agents learn and execute tasks, the team will collect performance data—e.g., arithmetic intensity, cache misses, energy usage—on the scientific applications and software libraries using the agents. This multimodal data, along with intermediate representations in graph form, will then feed back into the agents for fine tuning. Further augmenting the training datasets will be synthetic data generated for a spectrum of programming languages—like Fortran, in which many legacy codes are written, and Julia and Rust, which are still gaining traction.
Another project goal is user interaction with the HPC-LLM agents. During code generation, Menon explains, “The agent can provide an output for the user to approve, or the user can input a new requirement such as modifying an attribute. The user can correct behavior or provide additional guidance to the model.” Error messages, new prompts, and other user-elicited data can help improve the agents’ predictions.
The resulting workflow is a loop of iterative sensing, planning, and acting (see figure below). Menon adds, “Parallel code generation can’t be done well in one shot. We are decomposing the process into multiple sub-tasks that specialized HPC-LLM agents can handle.” These specialized agents will target tasks such as performance profiling, code compiling, and source code generation.
Additionally, the team will develop ways to validate data quality, verify model outputs, and improve model interpretability. This work will include expanding state-of-the-art benchmarking capabilities to enhance attribution and prediction accuracy, as well as building datasets of reasoning tasks that are currently unsolvable by Code LLMs. “A major challenge for this project will be ensuring that the LLM-generated code is both correct and efficient for HPC applications,” cautions Menon. “Given the complexity of HPC code, verifying the correctness and performance of the generated code becomes important.”
Next-Generation Software
The DOE’s Exascale Computing Project (ECP), which ran during 2016–2024, produced the Extreme-scale Scientific Software Stack (E4S)—a large, high performance portfolio of exascale-ready software libraries and tools. With the ECP now concluded, the E4S is critical for HPC centers like LLNL to sustain. Menon’s team plans to demonstrate their approach on the E4S, thus benefiting the broader HPC community and other research institutions with exascale platforms. “We aim to reduce the cost of E4S stewardship and accelerate its adoption, extending DOE’s investments in ECP software,” explains Menon.
By leveraging LLMs, the team is adapting to industry advancements while responding to DOE’s unique needs. Menon states, “Code development will change quite a bit in the coming years. We have to be ready for the next generation of students who will interact differently with simulations and code.”
With $7 million in funding through the Advanced Scientific Computing Research program within the DOE’s Office of Science, this three-year project is a collaboration with Oak Ridge National Laboratory, the University of Maryland, and Northeastern University. The team’s combined expertise spans performance-portable software and tools, the LLVM compiler, machine learning for HPC, foundational artificial intelligence, and LLMs for code generation. Alongside Menon, Livermore team members are Tal Ben-Nun, Kshitij Bhardwaj, Siu Wun Cheung, Todd Gamblin, Giorgis Georgakoudis, Konstantinos Parasyris, and Gautam Singh with plans to onboard another postdoctoral researcher and two student interns.
— Holly Auten