
Researchers from the Center for Applied Scientific Computing (CASC) received an Outstanding Paper recognition at the 2023 IEEE High Performance Extreme Computing (HPEC) conference. In “Leveraging Mixed Precision in Exponential Time Integration Methods,” Cody Balos, Steven Roberts, and David Gardner explored a unique intersection of mathematical algorithms, computational efficiency, and machine learning (ML)–oriented processors.
“The industry is producing hardware that works well for ML, and we wanted to investigate its potential for traditional scientific computing simulations,” says Balos, the paper’s lead author. Examples of LLNL’s investments in ML-specific hardware include integration of Cerebras Systems’ ML chip into the petascale Lassen supercomputer (shown in the photo above) and SambaNova Systems’ data flow accelerator into the Corona supercomputing cluster.
A large-scale simulation’s accuracy—and expense—increases with higher levels of computational precision, but ML processors often perform better with low precision. So how can the former run on the latter and still produce meaningful results? One answer lies in time integration methods and mixed-precision computing.
Time integration methods solve ordinary differential equations, which describe physical phenomena in many scientific simulations. A class of these methods, known as exponential integrators, may be well suited to ML processors because of the underlying linear algebra operations. Balos explains, “Exponential methods involve a lot of linear algebra operations which are also common in neural networks that underpin many ML algorithms. So we reformulated two exponential methods to use mixed precision and make the most of the new hardware.” Mixed-precision computing switches between lower precisions, such as half (16 bits) or single (32 bits), and double (64 bits) within a calculation, improving a simulation’s overall computational efficiency while retaining the higher precision accuracy.
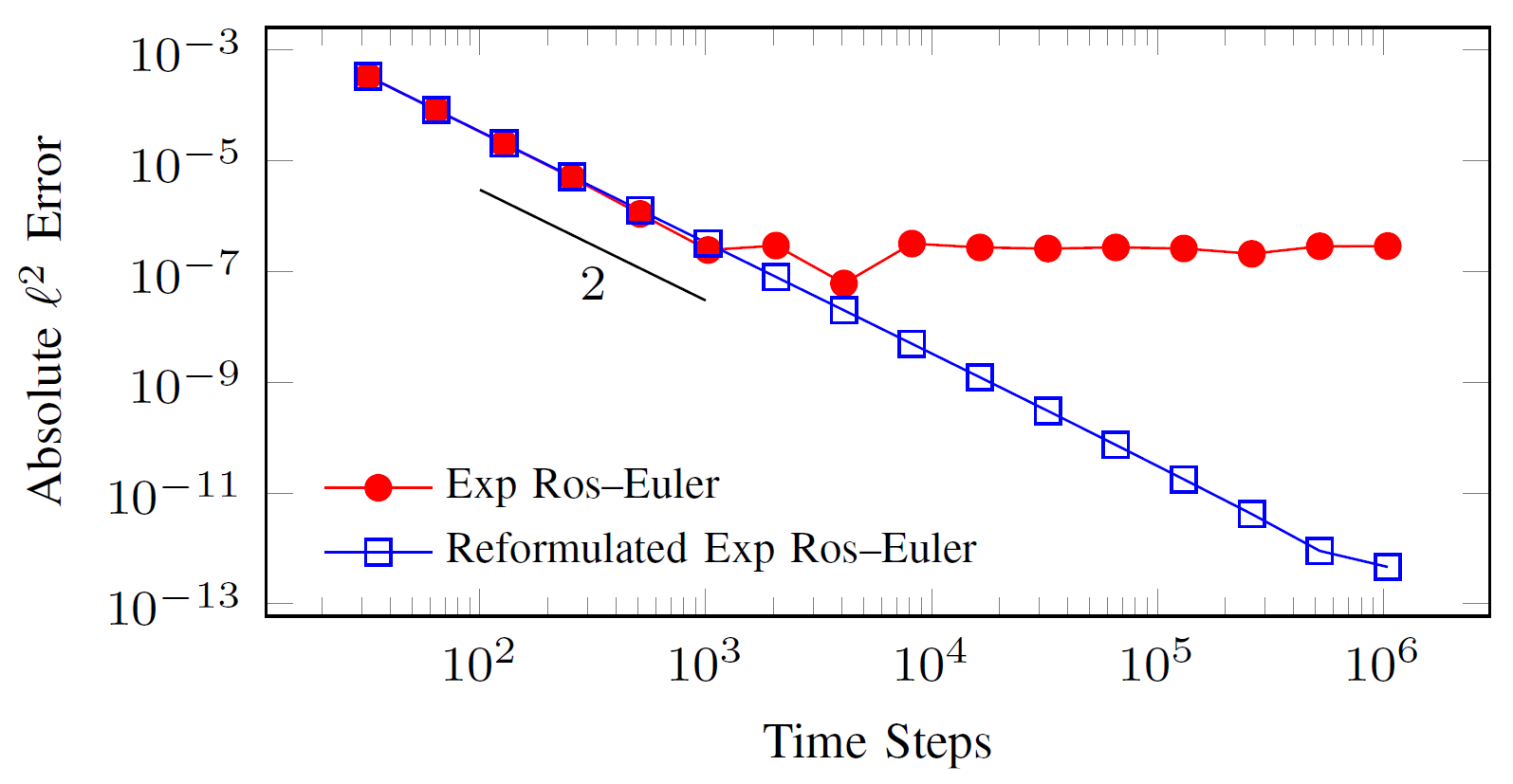
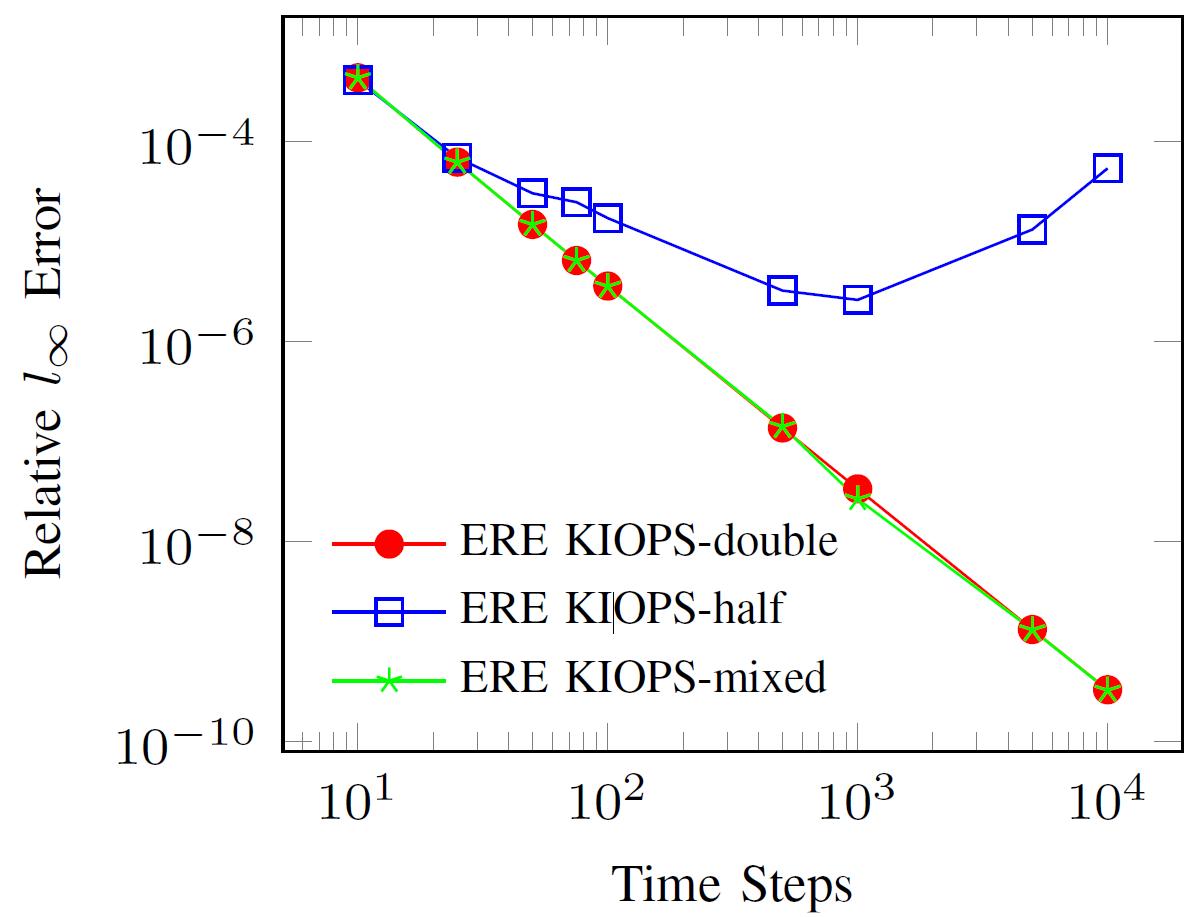
Supported by the Laboratory Directed Research and Development program, the team tested their enhanced exponential methods on an advection-diffusion-reaction problem relevant to the Lab’s fluid flow and combustion simulations. The results demonstrated better accuracy than single precision and better efficiency than double precision. Balos points out, “We were able to achieve the same accuracy with lower precision as we would have with double precision. With this scheme, simulations could potentially run faster without sacrificing accuracy.”
The CASC team’s work presents a compelling direction for time integration methods as more exascale supercomputers—including LLNL’s imminent El Capitan system—come online. For Balos, the interplay between hardware and numerical algorithms brims with possibilities. “We may have the opportunity to use these systems’ lower precision capabilities,” he states. “And beyond exascale, we may be able to speed up scientific applications by incorporating ML hardware in innovative ways.”
In addition to this paper, two other CASC-affiliated teams were selected among IEEE HPEC’s Outstanding Student Papers. Pei-Hung Lin and Chunhua Liao co-authored “Creating a Dataset for High-Performance Computing Code Translation using LLMs: A Bridge Between OpenMP Fortran and C++” with LLNL student intern Le Chen and others from the University of Connecticut, while Trevor Steil and Roger Pearce co-authored “Optimizing a Distributed Graph Data Structure for K-Path Centrality Estimation on HPC” with intern Lance Fletcher.
—Holly Auten