
Power GREMLINS
Performance optimization under a power bound is the primary novel challenge of exascale computing. To explore this space, developers need to understand the power characteristics of their code as well as how it reacts to low-power scenarios. Our Power GREMLIN enabled measuring and capping both cpu package and DRAM power by using the Running Average Power Limit (RAPL) technology on Intel processors.
Thermal GREMLINS
Performance at exascale will not only be constrained by power but by thermal considerations as well. In addition, continuous execution at high power requires active cooling which in turn consumes more power. Our Thermal GREMLIN allows developers access to per-core temperature sensors to track how code creates heat. We are exploring the possibility of augmenting this gremlin with an interface to package thermal capping: when the processor reaches the user-specified limit, performance degrades until the lower temperature is restored.
Resilience GREMLINS
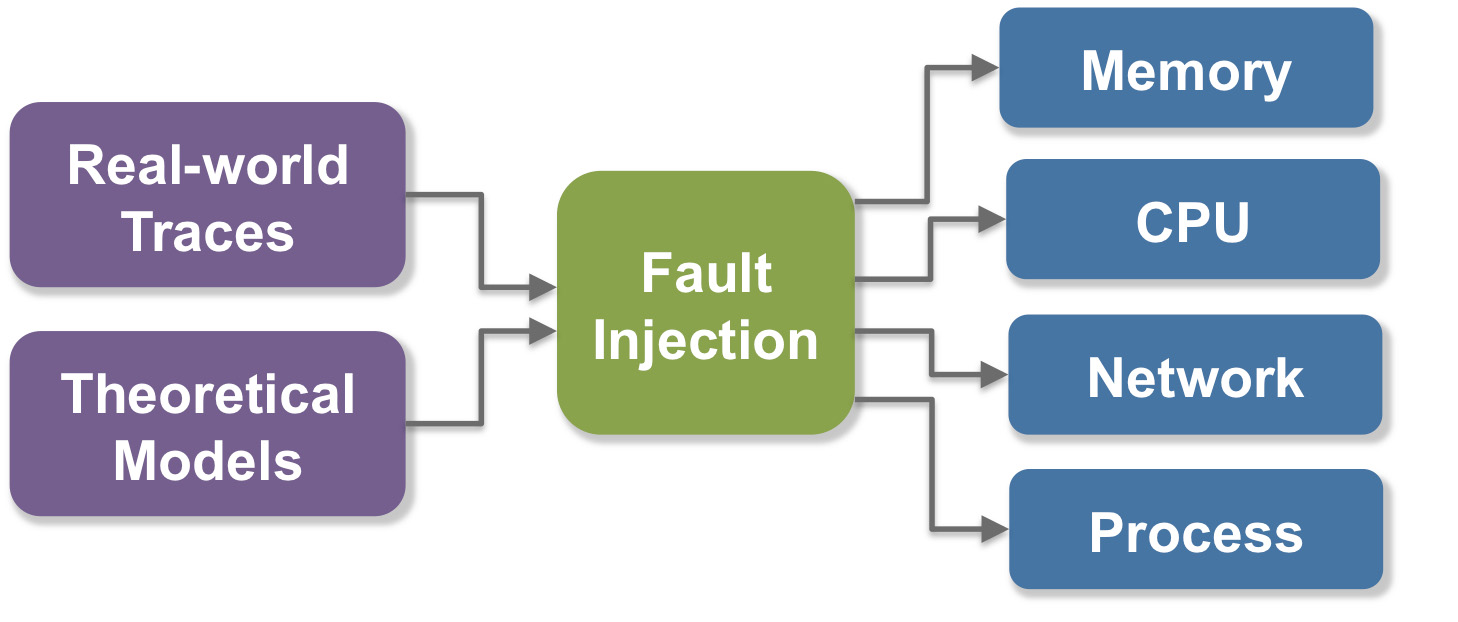
Designing fault-tolerant programming models and recovery techniques requires evaluating them with real-world faults and errors. The resilience GREMLINS inject faults into target applications at specified rates and distributions, which emulate the characteristics of real-world faults. This enables us to study the efficiency and correctness of future middleware- and application-level recovery techniques.
Our fault injection strategy involves emulating faults from multiple components of the system: processor instruction faults, memory errors, network errors, and process failures. Our goal is to study the efficiency of fault recovery paradigms such as:
- Code block re-execution: via annotations, programmers can protect code regions using semantics similar to try/catch statements. When an instruction fault occurs, the code region is simply re-executed.
- Data reconstruction: network errors are handled by packet retransmissions, which can be expensive operations. Instead of incurring high overheads by retransmitting data, we let the application know about errors. The application can reconstruct lost data or discard the error.
- Replication in space and time: parallel processes can fail, e.g., due to a node crash. We are designing mechanisms to store critical data in neighbor processes or nodes. When a node crashes, the application can continue with the rest of the healthy nodes.
Bandwidth and Memory GREMLINS
By running carefully-calibrated threads alongside codes of interest, we can emulate reduced bandwidth and capacity across the whole of the memory hierarchy.
Latency GREMLINS
Latency GREMLINS expose the PEBS interface on Intel processors to allow us high-fidelity, per-load latency measurements. We are exploring several options that will allow us to degrade latency, thus simulating the more complex memory hierarchies in future exascale designs.
Noise GREMLINS
Noise GREMLINS allow injection of delays ranging from nanoseconds to milliseconds and can be specified as part of a specified random, time-dependent distribution. As core counts increase by multiple orders of magnitude, rare noise events become more common. This gremlin allows us to simulate what noise might be like on an exascale cluster.