
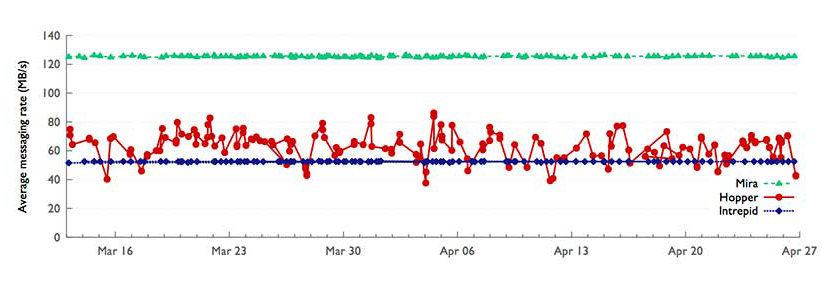
Message passing can take up a significant fraction of the runtime for massively parallel science simulation codes. Consistently high message passing rates are required for these codes to deliver good performance. Our studies show that run-to-run variability in message passing rates can reduce throughput by 30% or more due to contention with other jobs for the network links. Thus, we set out to investigate the possible sources of such performance variability on supercomputer systems.
Predictable performance is important for understanding and alleviating application performance issues; quantifying the effects of source code, compiler, or system software changes; estimating the time required for batch jobs; and determining the allocation requests for proposals. Our experiments show that on a Cray XE system, the execution time of a communication-heavy parallel application ranges from 28% faster to 41% slower than the average observed performance. Blue Gene systems, on the other hand, demonstrate no ;noticeable run-to-run variability. We investigate potential causes for performance variability such as OS jitter, shape of the allocated partition, and interference from other jobs sharing the same network links. Reducing such variability could improve overall throughput at a computer center and save energy costs.
Publications
Abhinav Bhatele, Kathryn Mohror, Steven H. Langer, and Katherine E. Isaacs. There goes the neighborhood: performance degradation due to nearby jobs. In submission to Supercomputing 2013 (SC '13), 2013. LLNL-CONF-635776.