
Spindle is a tool for improving the library-loading performance of dynamically linked HPC applications. At a high level, Spindle:
- Provides a mechanism for scalable loading of shared libraries, executables and python files from a shared file system at scale without turning the file system into a bottleneck.
- Is a pure user-space approach. Users do not need to configure new file systems, load modules into their kernels or build special system components.
- Operates on stock binaries. No application modification or special build flags are required.
- Automatically detects libraries as they’re loaded, so there is no need for pre-generated lists of libraries. Spindle can scalably load the targets of dlopen calls, dependencies, or libraries loaded by forked child processes.
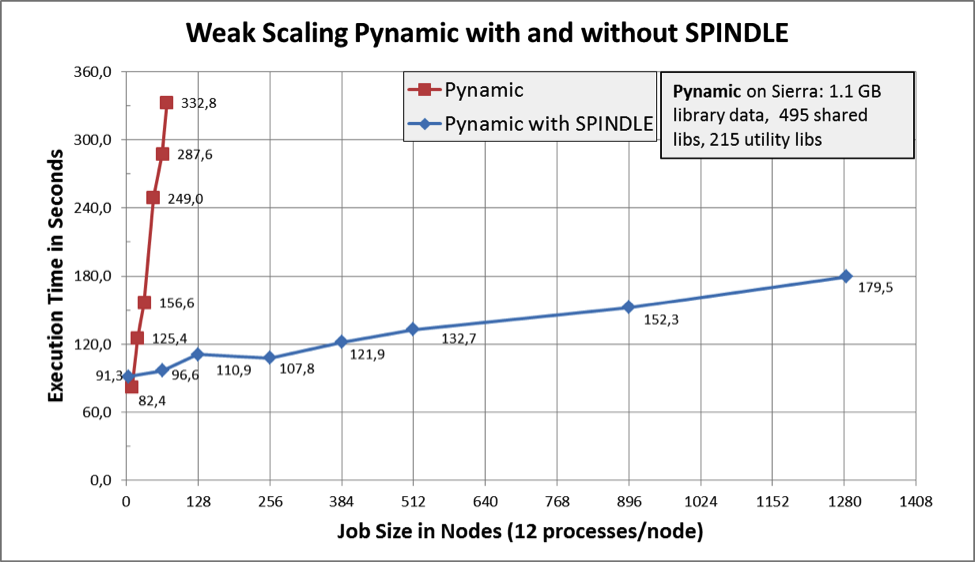
- Is very scalable. Under one benchmark, start-up performance without Spindle at 64 nodes was similar to start-up performance with Spindle at 1280 nodes—a performance improvement of 20X! And many applications will likely get better benefits from Spindle than this benchmark.
- Operates on Linux/x86_64 systems. Cray and BlueGene/Q ports are underway.
How Spindle Works
When a dynamically-linked application starts it needs to load its dependent dynamic libraries from disk. This is done by the dynamic linker, a system library loaded into each process, which is usually named something like /lib64/ld-linux.so. The dynamic linker will search through a list of directories on what is known as its search path and test them for the existence of the application's dynamic libraries. For an application running across N processes, this can produce O(N * num_dependent_libraries * num_search_path_entries) file operations. This number can grow very large at scale and easily overwhelm even high-bandwidth parallel file systems.
Spindle plugs into the system's dynamic linker and intercepts these file operations. Instead of allowing every process to do file operations and flood the file system, one process (or a designated small number) will perform the file operations necessary for locating and loading dynamic libraries, then share the results of those operations with other processes in the job.
The results of those file operations will be things like file or directory contents. File contents are stored in a local location on each node, such as a ramdisk or SSD, and Spindle directs the application to load libraries from these locations rather than the shared file system.
As a high-level simplified example, consider an application that is running on 4 nodes and trying to load a library libfoo.so:
- Processes 0-3 each start to load libfoo.so
- Spindle designates one process, such as process 0, as responsible for libfoo.so. Process 0 loads libfoo.so from disk while processes 1-3 block.
- Process 0 scalability broadcasts the contents of libfoo.so to the ramdisks on the nodes running processes 1-3 and stores libfoo.so in its own ramdisk.
- Process 0-4 load libfoo.so from the ramdisk and continue running.
Spindle can apply these concepts to other files besides shared libraries, and does similar operations for Python .py and .pyc files.
Publications and Talks
Wolfgang Frings, Dong Ahn, Matthew LeGendre, Todd Gamblin, Bronis de Supinski, Felix Wolf. Massively Parallel Loading. In Proc. of the 27th International Conference on Supercomputing, Eugene, OR, USA, pages 389–398, ACM, June 2013. LLNL-CONF-610893