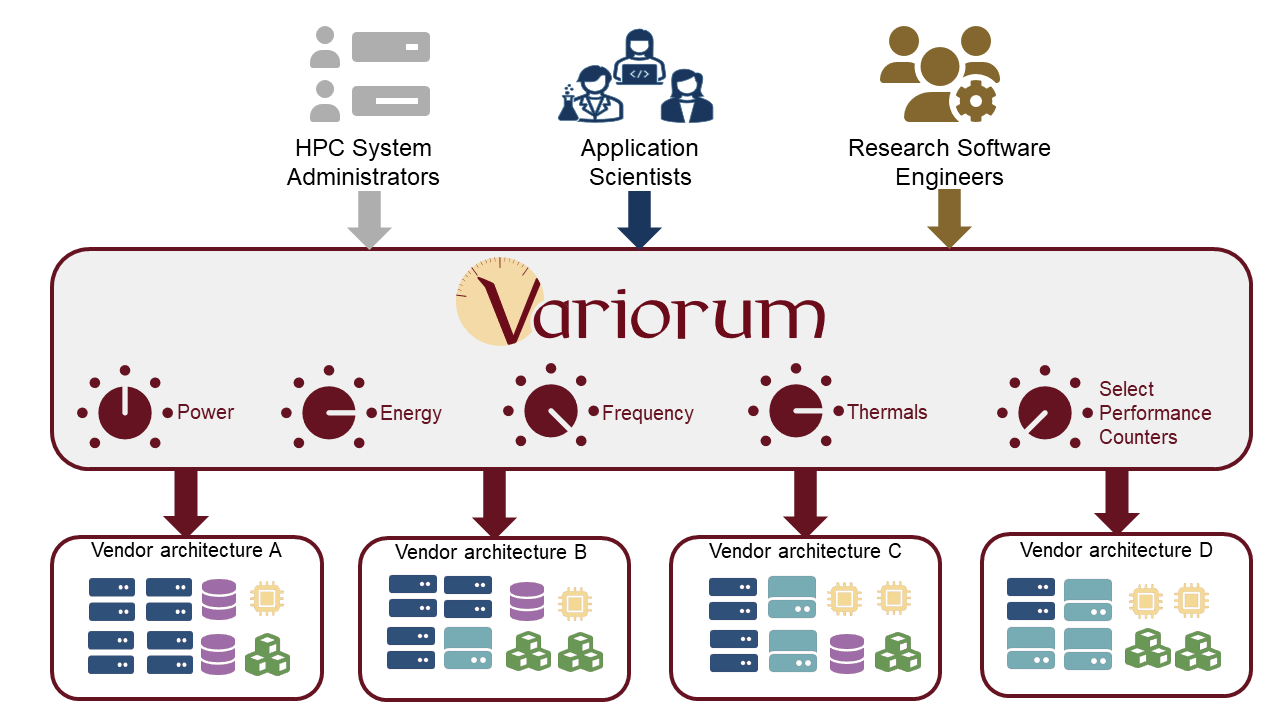
Optimizing and managing power and energy on large-scale supercomputers is critical for many reasons. Efficient systems can process more user requests and improve the pace of scientific discovery. Additionally, understanding the power and energy costs allows for better utilization and environmentally friendly supercomputing practices. An HPC system’s power and performance are affected by configurations and requirements at different levels of the system, and each level presents challenges—and opportunities—for optimization. The most granular level is on the individual nodes, where the most impactful monitoring, managing, and optimizing of power and performance can (and should) occur via precision tuning of a multitude of low-level options, or “dials” as on a radio or sound engineer’s board. This lowest level is the key to the hierarchy above it. These low-level dials, however, are complex and vary significantly across vendors and are often poorly documented. While some dials are obscured by specific hardware and software configurations, others have nonstandard interfaces that lack portability to other systems and are challenging to integrate into user applications.
Supercomputer users have varied backgrounds and include application and domain scientists, research software engineers and system administrators. Often, users are not familiar with low-level architecture details across different vendors, and some power and performance dials require the user to have elevated privileges. As a result, accessing power and performance optimization dials that are complex and vendor-specific can be chaotic, unwieldy, and error-prone from the users’ perspective.
Variorum’s application programming interface (API) abstracts out the details of the vendor-specific implementations and makes dials available to both general and advanced users in a portable manner. In its internal implementation, Variorum makes use of the different kernel interfaces, such as model specific registers (MSRs) on Intel and AMD or NVML for NVIDIA, to expose the available dials on the platform. These dials allow for measurement and control of various physical features on processors and accelerators, such as power, energy, frequency, temperature, and performance counters. Currently, Variorum supports several vendors and multiple generations of their microarchitectures.
As part of the Exascale Computing Project’s Argo Project and a key component for node-level power management in the HPC PowerStack Initiative, Variorum is successfully integrated with production-level system software in the PowerStack. Variorum interfaces with other production-level software designed for resource management such as Flux, runtime systems such as GEOPM and Kokkos, and monitoring software such as Caliper and the lightweight distributed metric service, or LDMS.
Variorum not only provides power management features for system level software, but it can also enable scientific applications to directly monitor system power during execution. For example, the Multiscale Machine-Learned Modeling Infrastructure (MuMMI) workflow, which is an award-winning workflow for cancer research on the Sierra supercomputer, can interface with Variorum at both the simulation level as well as the Flux job manager level.