
Disclaimer: This article is more than two years old. Developments in science and computing happen quickly, and more up-to-date resources on this topic may be available.
Since kicking off in 2016, the Department of Energy’s (DOE) Exascale Computing Project (ECP) has prepared high performance computing (HPC) software and scientific applications for exascale-class supercomputers, which are powerful enough to process a quintillion (1018) calculations per second. During this time, Oak Ridge National Lab deployed the nation’s first exascale system known as Frontier, soon to be joined by Argonne National Lab’s Aurora and Livermore’s El Capitan.
A crucial part of the ECP’s success are co-design centers, which tackle exascale-related challenges common among the DOE complex and its collaborators. Optimizing a scientific application’s underlying mathematical solutions leads to better performance, so the Center for Efficient Exascale Discretizations (CEED, pronounced “seed”) focuses on efficient numerical methods and discretization strategies for the exascale era. (Read a CEED retrospective in the article ECP co-design center wraps up seven years of collaboration.)
Led by LLNL computational mathematician Tzanio Kolev, CEED recently held its seventh and final annual meeting—an event nicknamed CEED7AM. Hosted at LLNL’s University of California Livermore Collaboration Center and including online attendees, the meeting featured breakout discussions, more than two dozen speakers, and an evening of bocce ball. LLNL administrators Linda Becker, Kathy Hernandez Jimenez, Jessica Rasmussen, and Haley Shuey helped organize the event.
Common Threads

Interest in the center’s progress and results goes beyond the ECP. Among the participants in the August 1–3 meeting were researchers from 7 national labs and 24 universities, plus several commercial companies and a few student interns. Kolev stated, “Our users benefit from the experience and wisdom of multiple teams with different history and different perspectives.”
Code portability and GPU performance were common threads through many presentations. CEED team members and collaborators alike described their evaluation of and improvements to performance on multiple types of computing systems including Frontier, El Capitan’s early access systems, and the Perlmutter supercomputer at the National Energy Research Scientific Computing Center. Speakers also provided a glimpse into applications that rely on CEED software, such as additive manufacturing, radiation hydrodynamics, and fusion reactors.
Exascale Optimization
Tim Warburton, director of Virginia Tech’s Parallel Numerical Algorithms research group and the John K. Costain Faculty Science Chair, described CEED’s libParanumal project, which provides experimental finite element solvers for heterogeneous computing architectures. libParanumal features a variety of finely tuned linear solvers—an efficiency optimization Warburton compared to building a fast car. “It’s not enough to tune just the engine. You also need good brakes [error estimates], weight reduction [mixed precision], and improved roads [vendor co-design],” he said.
Researchers use libParanumal’s benchmarking capabilities to “do the detective work” on HPC systems, Warburton explained. He summarized CEED’s software development alongside the HPC industry’s hardware advances, noting, “GPUs have become more powerful during the center’s lifetime, and we add benchmarking tests as GPUs find new ways to surprise us. We have to look at the impact of our software design choices every time a new hardware component or architecture change is introduced.”
Indeed, CEED projects like libParanumal have been tested on several different architectures including early access systems for Frontier. Emphasizing the purpose of co-design, Kolev added, “Being part of the ECP has given us credibility with vendors who will listen to what we have to say.”
Multiscale Efficiency
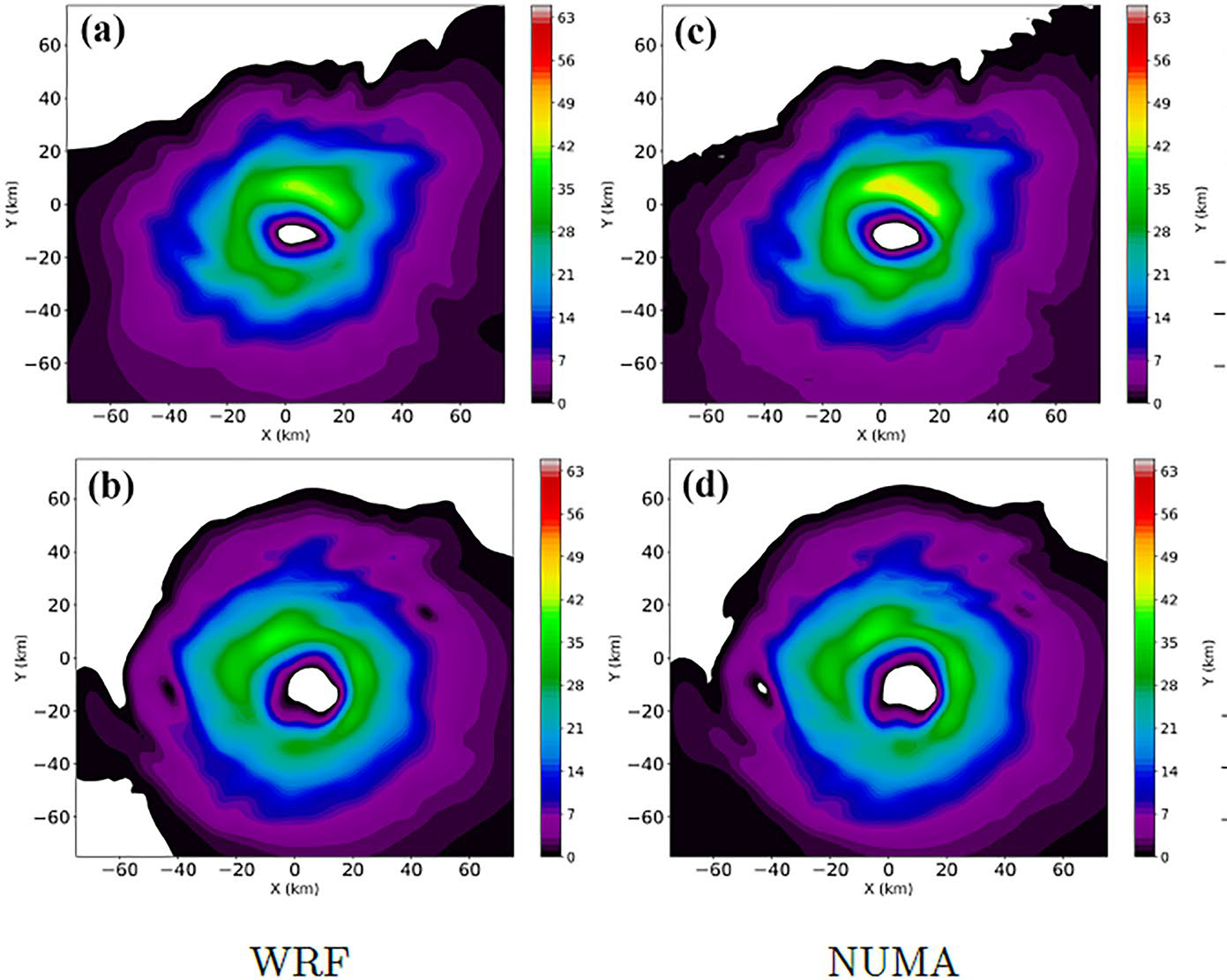
Numerical methods play a vital role in climate and weather research at the U.S. Naval Postgraduate School (NPS), where students and faculty in the Computational Mathematics Laboratory are exploring ways to refine the resolution of atmospheric circulation models. Frank Giraldo, NPS distinguished professor and Applied Mathematics Chair, presented his team’s work on hurricane simulations. (He gave a seminar on this topic at LLNL in June.)
“Tropical cyclone rapid intensification, where wind velocities increase quickly in a short period, is a difficult and important problem,” Giraldo explained. “We’re trying to understand hurricanes better and track them in a full global simulation.” For instance, hurricanes can be hundreds of kilometers in size; to properly capture the phenomena, large-eddy simulations should resolve at about 100 meters. The NPS-developed Nonhydrostatic Unified Model of the Atmosphere (NUMA) and its lightweight version (xNUMA) solve coarse- and fine-scale problems with a multiscale modeling framework, dynamic adaptive mesh refinement, and time integration strategies.
However, multiscale modeling requires many fine-scale simulations for each coarse-scale element. Giraldo pointed out, “These simulations are too computationally expensive to run on a regular basis, but you need the ability to do multiple simulations in order to advance science.” To reduce computational costs, his team is investigating solutions that leverage larger time-steps, reduced order models, or machine learning techniques.
Regardless of the approach, Giraldo emphasized that GPUs are necessary for processing complex 3D atmospheric simulations—particularly to achieve the National Weather Service’s mandate of generating a 24-hour forecast in just 8 wall-clock minutes. In past work, collaborating with Warburton and leveraging CEED’s OCCA portability library, Giraldo’s team successfully ran the NUMA code on Oak Ridge’s GPU-based Titan supercomputer.
Naval fleets depend on accurate oceanographic and meteorological predictions, and NUMA is the basis for the U.S. Navy’s NEPTUNE global atmospheric model, which will become operational in 2024. “The Navy has developed their own weather models for as long as numerical weather prediction has existed,” Giraldo noted.
'A Banner Year'
The CEED team hails from Livermore and Argonne national labs and five universities: Rensselaer Polytechnic Institute, University of Colorado at Boulder, University of Illinois Urbana-Champaign, University of Tennessee, and Virginia Tech. “The meeting’s large turnout, including many collaborators and users beyond our team, indicates that the scientific community is enthusiastic about what we’ve done and continue to do,” noted Kolev. “I enjoyed all the talks and learned something from all of them. There were some very interesting ideas that I want to follow up on.”
Warburton says he has been continually impressed by CEED’s progress over the years. He reflected, “Despite being located across the country, the leadership team has managed the project superlatively, and as everyone gathered to showcase their achievements, it was clear this was a banner year for the collaboration.” First-time attendee Giraldo added, “The quality of the presentations, as well as the discussions during and after, were all at the highest level.”
—Holly Auten