
Compiling large-scale application codes to run on modern high performance computing (HPC) systems is difficult. All codes have dependencies, hardware requirements vary, and no single programming language dominates the field. State-of-the-art solutions fall into two camps: ahead-of-time (AOT) and just-in-time (JIT) compilation. AOT compiles code before the application executes, which limits the number of program inputs and other variables the compiler can access. Alternatively, JIT adapts to conditions that unfold during runtime but with extra compilation overhead.
Graphics processing units (GPUs) further complicate the situation. Ideally, applications can take full advantage of massively parallel processing and perform well regardless of which GPU-based supercomputer they’re running on. The ideal compiler analyzes and optimizes the instructions from kernels within the source code as it runs, thus enabling the application to run efficiently on GPUs at scale. But most compilers reach a performance plateau, and JIT is considered impractical in an HPC setting.
However, a team from LLNL’s Center for Applied Scientific Computing (CASC) has developed a new JIT approach that leverages LLVM intermediate representation (IR) to optimize GPU kernels at runtime. Giorgis Georgakoudis, Konstantinos Parasyris, and David Beckingsale describe this solution in their paper “Proteus: Portable Runtime Optimization of GPU Kernel Execution with Just-in-Time Compilation,” which was accepted to the 23rd ACM/IEEE International Symposium on Code Generation and Optimization in March. Proteus is available on GitHub.
Smarter Compilation
IR is an important part of compilation because it simplifies code for analysis and optimization, while the widely available LLVM compiler framework supports JIT compilation and is adaptable to multiple languages and processors. Accordingly, the team decided to adopt LLVM IR as the foundation for their novel JIT solution.
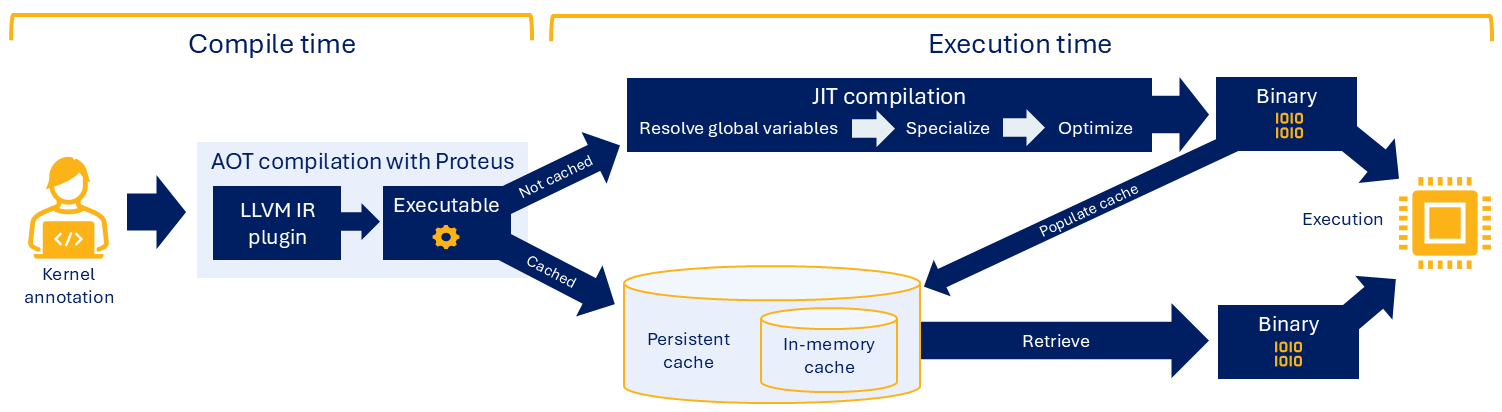
To begin, the developer annotates application functions and GPU kernels before compiling the code with Proteus, which runs in two phases (see Figure 1). First, it provides an LLVM IR plugin at AOT compile time. The plugin extracts the program variables and IR components that will be used for JIT compilation in the next phase.
As the application runs, Proteus automatically performs JIT compilation in the background, specializing annotated kernels as they execute and tailoring them to the specific input variables and runtime parameters extracted. Those specializations help eliminate unknowns as the compiler generates machine-readable code to enable more compiler optimizations. Remarkably, this dynamic code transformation incurs minimal runtime compilation overhead.
Cache Flow
Caching speeds up compilation and is therefore a key part of the Proteus workflow. The first time an application runs, JIT-compiled kernel binaries are saved to faster in-memory cache and afterward flushed to slower persistent cache on disk. The next time the application runs, cached data is retrieved from disk to memory—no recompilation needed—while new data is again stored temporarily in memory.
This two-level caching strategy saves each compiled binary with a unique identifier, which enables Proteus to determine where to store data and which data to retrieve. Users can clear the persistent cache if desired, such as when the source code changes significantly between runs.
Significant Speedups
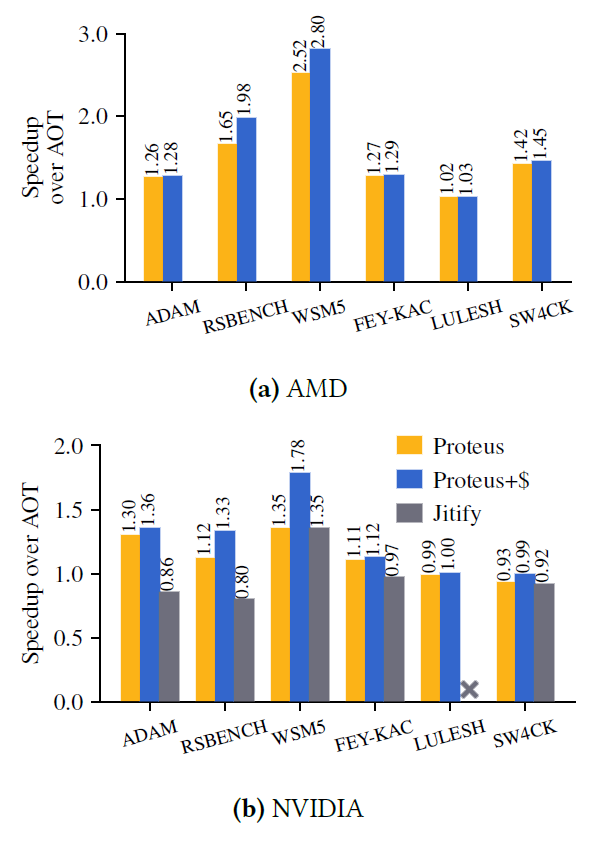
The team tested Proteus with benchmark GPU programs from different application domains (e.g., machine learning, weather forecasting, hydrodynamics) on Livermore’s heterogeneous Lassen and Tioga supercomputers. With end-to-end application speedups of up to 2.8x, Proteus is faster than AOT compilers and outperforms a vendor-specific JIT compiler (see Figure 2).
Proteus-enabled performance gains help HPC application teams reach their solutions faster. And these results demonstrate JIT compilation viability for large-scale applications on GPU-based computing architectures—a challenge to the conventional view that AOT compilation is the standard. Georgakoudis points out, “For the languages used in HPC, JIT has been considered an impossible task because the overhead is too large. This work proves that’s not true.”
Practical Portability
The LLVM IR plugin makes Proteus compatible with vendor variations across compilers and GPUs. With LLVM IR as a common denominator, JIT compilation is now available to static languages like C++ and Fortran that usually require AOT for fast application execution. “Any language that can be translated to LLVM IR can benefit from Proteus,” notes Georgakoudis.
Proteus also improves application teams’ productivity because they don’t have to rewrite their source code to accommodate new compilation tasks. “Optimizing ahead of time needs special code, which we can replace with runtime compilation,” says Beckingsale. Proteus is already integrated into a version of Livermore’s RAJA Portability Suite, providing seamless JIT compilation for large-scale codes that rely on these portability software libraries.
Two of the Laboratory’s mission-critical applications are already using this JIT-powered solution, and Proteus development continues. Beckingsale states, “The effort to implement the combined RAJA/Proteus solution into these codes was low. Any optimizations we add in the future can be applied to production codes with minimal changes.” Parasyris adds, “Since our paper came out, we’ve been working closely with the Lab’s code teams to make sure their needs are built into the compilation pipeline.”
—Holly Auten