A growing number of scientific computing applications must deliver high performance on central and graphics processing unit (CPU and GPU) hardware platforms. Compute node architectures are becoming more complex and diverse than earlier generation platforms as hardware vendors strive to deliver performance gains while adhering to physical constraints, such as power usage.
Moreover, DOE laboratories are procuring machines such as El Capitan (LLNL), Frontier (Oak Ridge), Aurora (Argonne), and Perlmutter (Lawrence Berkeley) with GPUs from three different hardware vendors. This environment makes developing applications that can run efficiently on multiple platforms increasingly time consuming and difficult.
The challenges are particularly acute for applications in the Advanced Simulation and Computing (ASC) Program, which are essential tools for the LLNL nuclear stockpile modernization mission. A typical large, integrated multiphysics code contains millions of lines of source code and tens of thousands of numerical kernels, in which a wide range of complex numerical operations are performed. Variations in hardware and parallel programming models make it increasingly difficult to achieve high performance without disruptive platform-specific changes to application software.
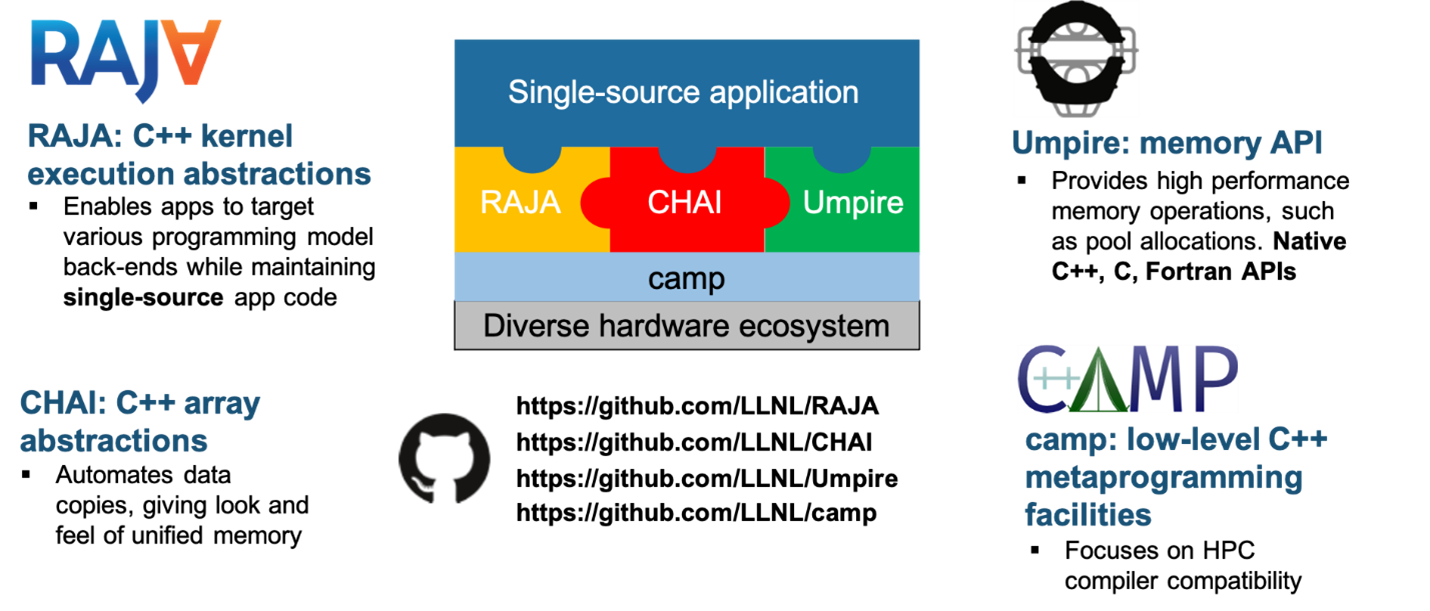
The RAJA Portability Suite is a collection of open-source software libraries that enable developers to build portable—meaning, single-source—high performance applications. The RAJA Portability Suite provides software abstractions that enable portable parallel numerical kernel execution (RAJA) and memory management for computing platforms with heterogeneous memory systems, specifically the Umpire and CHAI libraries. The RAJA Portability Suite development is supported by LLNL’s ASC Program, the RADIUSS project, and the DOE Exascale Computing Project (ECP). As open-source projects on GitHub (see links below), RAJA Portability Suite libraries have a growing community of users and contributors.
Portability Software Proven in Production
Most LLNL ASC applications plus a number of ECP applications and non-ASC LLNL applications rely on the RAJA Portability Suite to run on diverse platforms. LLNL’s institutional RADIUSS effort promotes external collaboration and funds integration of RAJA Portability Suite software into non-ASC applications. The RAJA Portability Suite has been central to LLNL’s ASC application GPU-porting strategy.
Table 1 shows the extent to which LLNL ASC program applications have adopted the RAJA Portability Suite to exploit the computational power of LLNL’s Sierra, the first GPU-enabled production system at LLNL with NVIDIA V100 GPUs comprising well over 90% of its compute power. These applications are thus well positioned to quickly adapt to new GPUs from AMD when El Capitan arrives in 2023–24. Meanwhile, they continue to run on CPU-based platforms with just a recompile, and the presence of RAJA allows for platform-specific optimizations for CPU features such as SIMD vectorization—all hidden from the application developer.
| Major LLNL ASC Program Applications | ||||||||
|---|---|---|---|---|---|---|---|---|
| Ares | ALE3D | Kull | MARBL | Ardra | Mercury | Teton | Hydra | |
| Language | C++ | C++ | C++ | C++ & Fortran | C++ | C++ | Fortran | C++/C |
| CPU/GPU Execution Model | RAJA | RAJA | RAJA | RAJA + MFEM & OpenMP | RAJA | CUDA & RAJA | OpenMP & CUDA-C (possibly RAJA) | Exploring OpenMP, CUDA, RAJA |
| Data Transfer | UM + Explicit | CHAI | UM | Explicit | CHAI | UM | Explicit | Explicit, Exploring CHAI |
| Memory Allocation | Umpire | Umpire | Umpire | Umpire | Umpire | Umpire | Umpire | Explicit, Exploring Umpire |
Figure 1 shows a sampling of ECP applications that have adopted RAJA Portability Suite capabilities to run on the diverse set of platforms in the DOE laboratory supercomputer ecosystem.

Robust and Flexible Software to Manage the Interplay Between Parallel Execution and Memory
Developers of ECP and production NNSA applications have reported that it is straightforward to integrate RAJA software into their C++ applications to enable them to run on new hardware, be it CPU or GPU based, while maintaining high performance on traditional computing platforms. Once integrated, the tools also enable platform-specific optimizations without major disruption to application source code.
In the RAJA Portability Suite, RAJA provides the parallel kernel execution API that is designed to compose and transform complex parallel kernels without changing the kernel source code. Implemented using C++ templates, this API helps insulate application source code from hardware and underlying programming model details allowing Subject Matter Experts (SME) to express the parallelism inherent in their calculations while focusing on writing correct code. The expression of parallelism requires basic knowledge of the underlying hardware platform and verification that application kernels will execute correctly in parallel.
The RAJA API enables a separation of concerns whereby developers with specialized performance analysis expertise can use RAJA abstractions to tune application performance for specific hardware platforms without disrupting application source code. RAJA developers also work to optimize and generalize RAJA features allowing multiple application teams to leverage their efforts. RAJA development encompasses the expertise of about 40 active contributors and 8 members of the core project team, plus vendor interactions to support new hardware from IBM, NVIDIA, AMD, Intel, and Cray. RAJA provides an array of parallel kernel execution interfaces to support a variety of loop and execution patterns, plus constructs for portable reductions, scans, sorts, and atomic operations.
Table 2 summarizes the main capabilities and parallel computing constructs that RAJA supports.
Simple & complete loop patterns and execution
| Loop transformations (without changing app code)
|
Multiple execution back-ends
|
|
Other tools in the RAJA Portability Suite provide portable memory management capabilities that complement RAJA parallel execution facilities. Umpire is a unified, portable memory management API focused on systems with heterogeneous memory resources. It provides capabilities for memory allocation/deallocation, copying, moving, and querying, plus flexible memory pools that are essential for maintaining high performance. Umpire’s introspection capability enables developers of components of integrated applications to make better decisions about sharing limited memory resources. It also supports allocations and other operations involving various memory types found on high performance computing (HPC) systems. Table 3 summarizes the capabilities that Umpire supports.
Intuitive concepts
| Features useful in HPC applications
|
Supported memory types
|
|
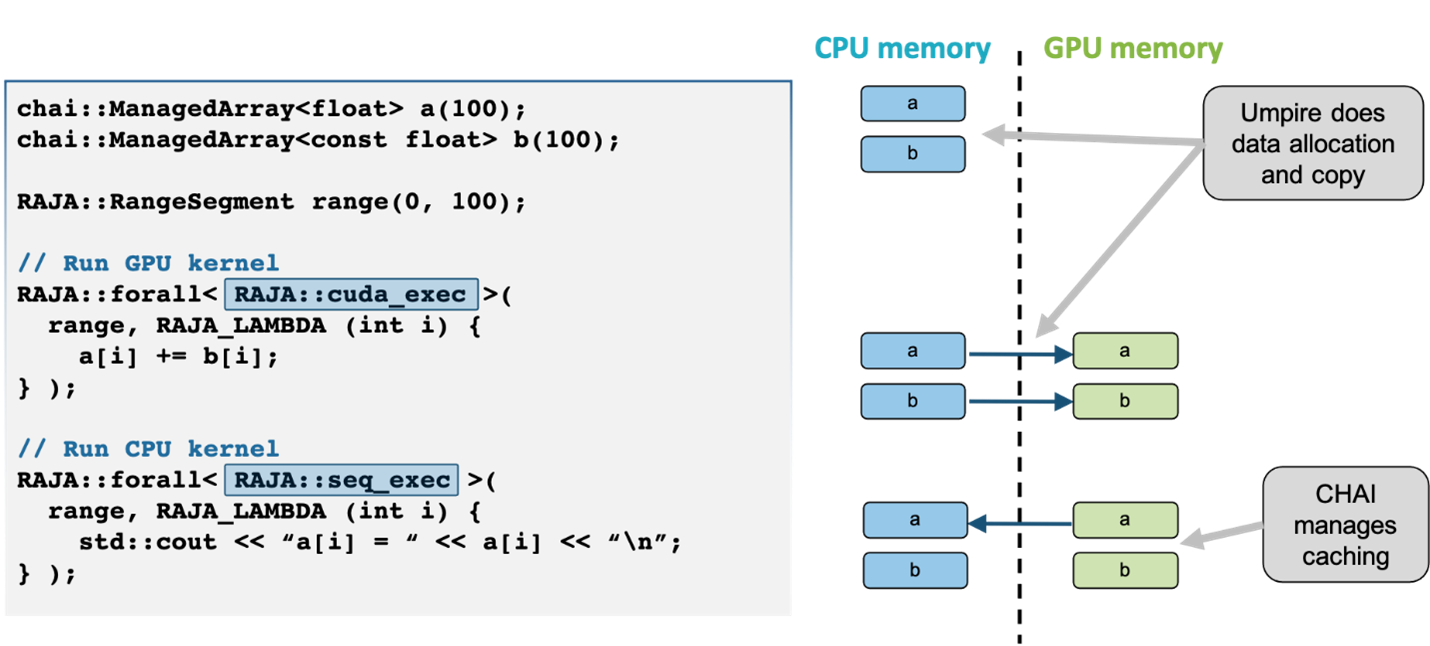
The CHAI library implements a “managed array” abstraction to automatically copy data, when required, to the memory space used by the device that will execute a RAJA kernel. CHAI relies on the Umpire package to provide a unified portable memory management API for CPUs and GPUs, and the C++ lambda capture that underpins RAJA to automatically identify variables to be managed. Figure 2 illustrates an example of how variables declared with CHAI’s managed types are automatically migrated between memory spaces with no additional source code, and the interaction between RAJA, CHAI, and Umpire.
Each of the RAJA, CHAI, and Umpire APIs is exposed to application programmers in common usage. The RAJA Portability Suite also utilizes a low-level collection of macros and C++ meta-programming facilities in the Concepts And Meta-Programming library (CAMP). A key goal of CAMP is to achieve wide compiler compatibility across HPC-oriented systems, thus helping to ensure portability and longevity of RAJA Portability Suite components and other libraries as HPC systems and the C++ language evolves. Typically, CAMP is not directly exposed to application programmers. However, they may use it in their applications as needed.
Figure 3 illustrates the complete RAJA Portability Suite library ecosystem and the relationship of the individual components to applications and hardware.