
zfp was designed primarily to serve as a compressed-array primitive, and supports both read and write random access to elements of multidimensional arrays in worst-case constant time. zfp partitions d-dimensional arrays into small blocks of 4d values, and these blocks are compressed or decompressed on demand as array accesses are made. Such compression on demand is often referred to as inline compression.
zfp's compressed arrays allow the user to specify how many bits of compressed storage to allocate to each array. The actual precision supported by such an array depends on how well the data it stores compresses and may vary spatially from one block to another. Alternatively, the user can fix the precision or set an absolute error tolerance, which results in a variable number of bits per block. Once declared, the user may interact with the compressed array using flat or multidimensional indexing via the usual array index operators; e.g., a[i + nx * j] and a(i, j) both reference a scalar (of type float or double) with index (i, j) in a 2D array of dimensions nx * ny. Through C++ operator overloading, the user may perform mixed read and write computations like a[i] += a[i-1] and need not even know that the array is stored compressed. As such, zfp arrays serve as a drop-in replacement for standard C/C++ arrays and STL vectors, and can often be substituted into applications with minimal code changes. zfp also supports indirect array access via iterators, proxy pointers and references, and views.
To limit the number of compression and decompression calls, zfp makes use of a small software cache of uncompressed blocks, which is consulted upon each access. If the block containing the requested array element is not present in the cache, it is fetched, decompressed, and stored in the cache. When a block is evicted from the cache, it is compressed back to permanent storage only if it has been modified.

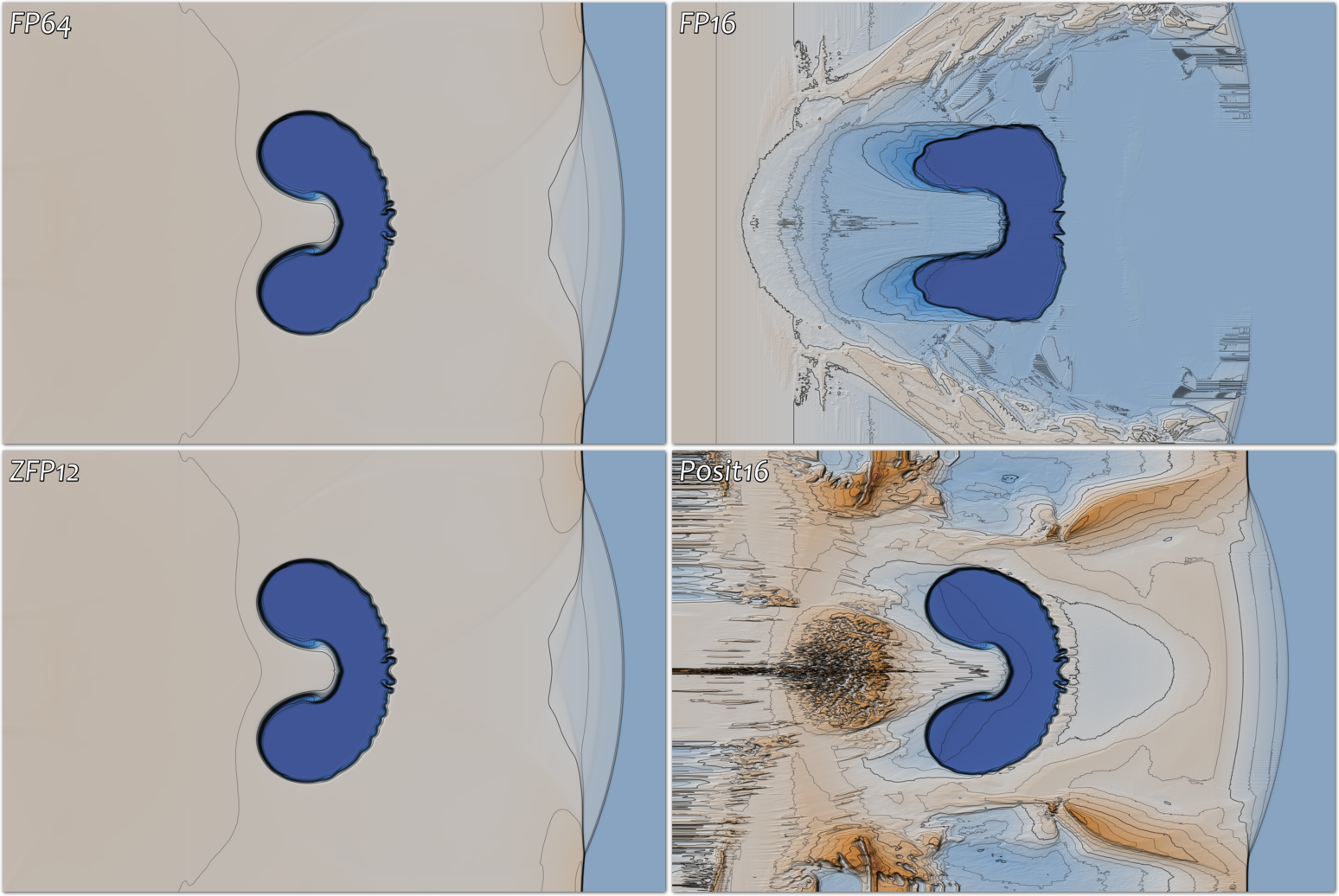
Another important application of zfp arrays is in-memory storage of state and large tables in numerical simulations. zfp arrays reduce the memory footprint and may even speed up severely memory bandwidth limited applications. The figure below illustrates how zfp arrays are used in a 2D simulation of a shock-bubble interaction. The figure shows the final-time density field resulting from computing on simulation state arrays (e.g., density, pressure, velocity) represented as conventional 64-bit and 16-bit IEEE floating point (top row) and 12-bit zfp and 16-bit Posit arrays (bottom row). As is evident, at less than five times the storage, zfp arrays give essentially identical simulation results to 64-bit double-precision storage, while the competing 16-bit representations show significant artifacts. For the simulations below, running with compressed arrays took 2.5 times as long as running with uncompressed floats or doubles, though in read-only applications such as ray tracing we have observed reduced rendering time using compressed arrays.
zfp's compressed-array classes are written in C++, though C wrappers around those classes are also available. We anticipate making bindings for other languages available in the future.