
HPC systems use checkpoint-restart for tolerating failures. Typically, applications store their states in checkpoints on a PFS. As applications scale up, checkpoint-restart incurs high overheads due to contention for overloaded PFS resources, forcing large-scale applications to reduce checkpoint frequency and, thus, lose compute time in the event of failure.
To alleviate these problems, we developed a scalable checkpoint-restart system, mcrEngine. mcrEngine aggregates checkpoints from multiple application processes with knowledge of the data semantics available through widely used I/O libraries (e.g., HDF5, netCDF) and compresses them. Our novel scheme improves compressibility of checkpoints up to 115% over simple concatenation and compression. Our evaluation with large-scale application checkpoints show that mcrEngine reduces checkpointing overhead by up to 87% and recovery overhead by up to 62% over a baseline with no aggregation or compression.
Inter-Process vs Intra-Process Similarity
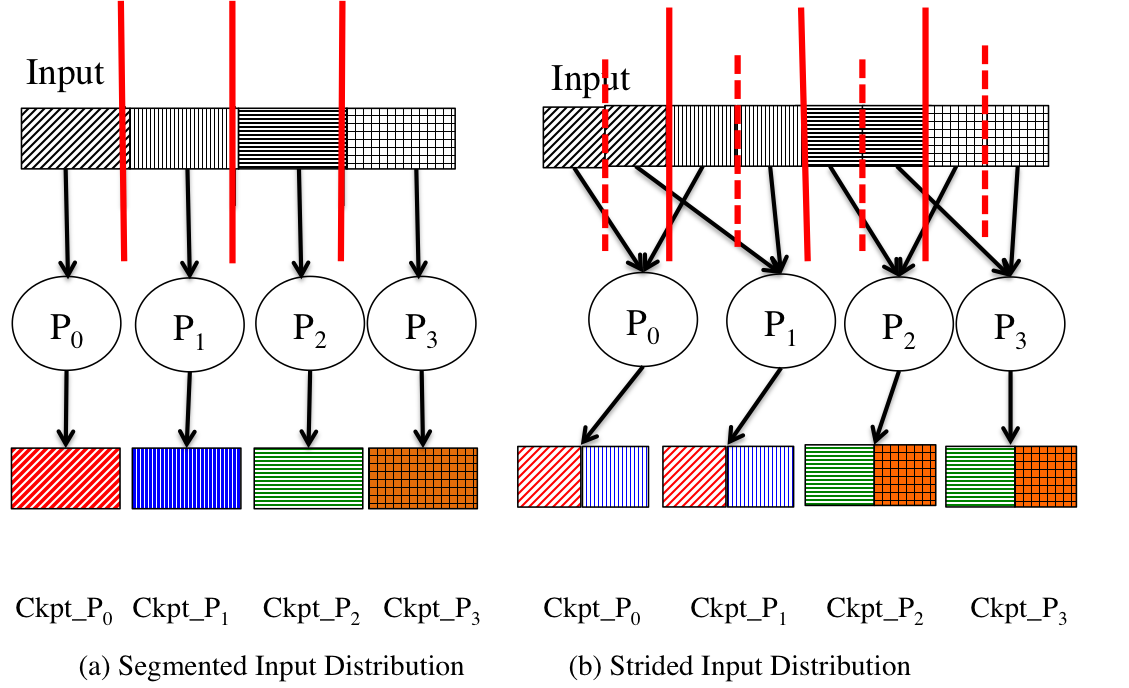
The figure above provides a high-level view of how input distribution can be responsible for introducing similarity in either intra- or inter-process checkpoints. Checkpoints generated from (a) have similarity in variables within a checkpoint than across process checkpoints. On the other hand, the opposite is true for checkpoints generated by processes in (b).
"Data-Aware" Compression
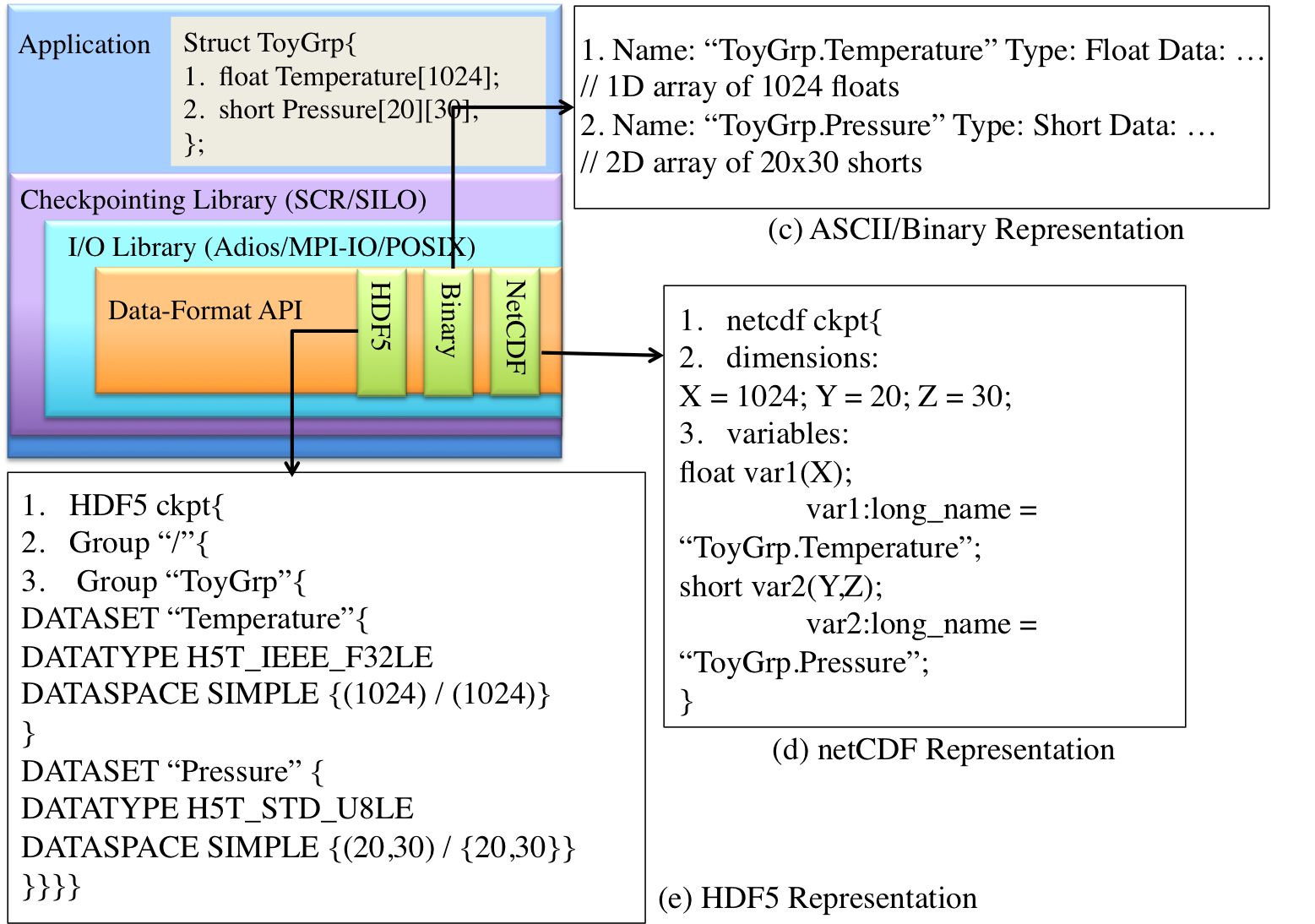
Essentially, we investigate this question: “If we knew better about the meaning of data actually written in these checkpoints, could we compress them more effectively?” Taking the meaning of data in order to better compress across-process checkpoints is what we call “data-aware” compression. We extract meanings of data from checkpoints by looking at annotations for each variable provided by various high-level data description libraries, such as HDF5 and netCDF. When application developers use these libraries to write checkpoints in portable formats, they provide us with potential clues to how to view the data written in these checkpoints. This makes our technique transparent to application developers already using these libraries to write their checkpoints. The rationale is that having all variables storing temperature data close together may improve compressibility of these checkpoint files that are otherwise known to be hard to compress.
Above, figures (c), (d), and (e) illustrate different ways users can make semantic information available. A number of large-scale applications already use hierarchical data formats such as HDF5 and netCDF to annotate their output files for better portability across multiple architectures. These applications can apply our technique to their data at no extra programming cost.
Similarity-Aware Checkpoint Aggregation + Data-Aware Compression = mcrEngine
In addition to developing a new compression technique, we designed and implemented an end-to-end system called mcrEngine. During the checkpointing phase, our system (1) reads checkpoints from disk after an application generates them, (2) aggregates checkpoints from multiple processes of the same application on an aggregator node, (3) applies data-aware compression, and (4) writes a large merged-compressed data to PFS. In a failure scenario, mcrEngine performs the necessary steps in reverse to regenerate required checkpoints from the PFS in order for an application to restart.