
Understanding the role file systems play in efficient checkpointing is essential. Many large-scale HPC systems do not provide file storage on compute nodes, preventing the use of SCR. Accordingly, we have implemented a novel user-space file system called CRUISE, which stores data in main memory and transparently spills over to other storage, like local flash memory or the PFS, as needed. This technique extends the reach of libraries like SCR to systems where they otherwise could not be used.
Furthermore, we expose file contents for remote direct memory access (RDMA), allowing external tools to copy checkpoints to the PFS in the background with reduced CPU interruption. Our file system scales linearly with node count and delivers a 1-petabyte/second throughput at 3 million MPI (message passing interface) processes, which is 20x faster than the system RAM disk and 1000x faster than the PFS.
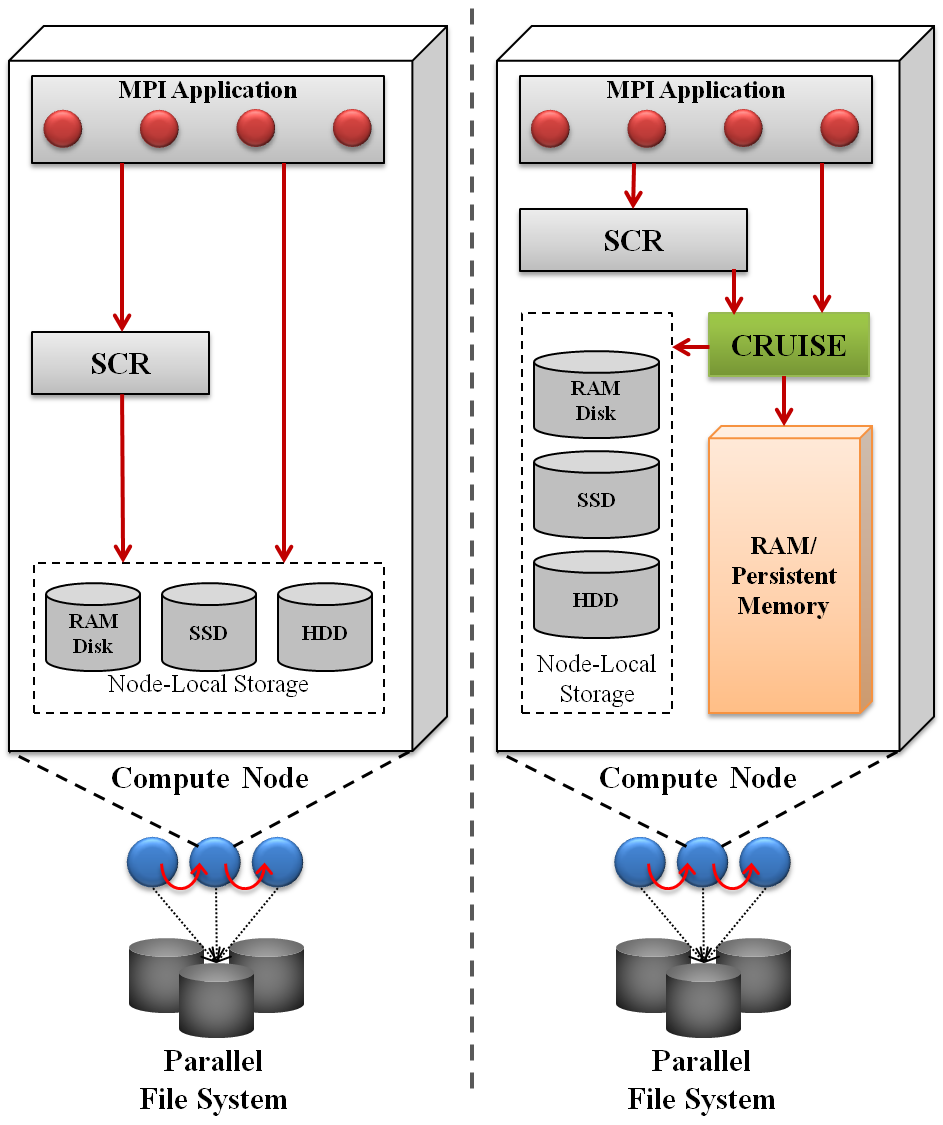
This figure depicts a high-level view of the interactions between components in SCR and CRUISE. On the left is the current state-of-the-art with SCR, and on the right is SCR with CRUISE. In both cases, all compute nodes can access a PFS. Additionally, each compute node includes some type of node-local storage media such as a spinning disk, a flash memory device, or a RAM disk.
In the SCR-only case, the MPI application writes its checkpoints directly to node-local storage, invoking the SCR library to apply cross-node redundancy schemes to tolerate lost checkpoints due to node failures. For the highest level of resiliency, SCR writes a selected subset of the checkpoints to the PFS. By using SCR, the application incurs a lower overhead for checkpointing but maintains high resiliency. Note that SCR cannot be employed on clusters with insufficient node-local storage.
In the SCR-CRUISE case, checkpoints are directed to CRUISE, and all application I/O operations are intercepted by the CRUISE library. File names prefixed with a special mount name are processed by CRUISE, while operations for other file names are passed to the standard POSIX (portable operating system interface) routines. CRUISE manages file data in a pre-allocated persistent memory region. Upon exhausting this resource, CRUISE transparently spills remaining file data to node-local storage or the PFS. This configuration enables applications to use SCR on systems where there is only memory or where node-local storage is otherwise limited.
The CRUISE file system is maintained in a large block of persistent memory. The size of this block can be specified at compile time or run time. So long as the node does not crash, this memory persists beyond the life of the process that creates it so that a subsequent process may access the checkpoints after the original process has failed. When a subsequent process mounts CRUISE, the base virtual address of the block may be different. Thus, internally all data structures are referenced using byte offsets from the start of the block. The memory block does not persist data through node failure or reboot. In those cases, a new persistent memory block is allocated, and SCR restores any lost files by way of its redundancy schemes.
RDMA allows a process on a remote node to access the memory of another node, without involving a process on the target node. The main advantage of RDMA is the zero-copy communication capability provided by high performance interconnects such as InfiniBand. This allows the transfer of data directly to and from a remote process’ memory, bypassing kernel buffers. This minimizes the overheads caused by context switching and CPU involvement.
Given that the data managed in CRUISE is already in memory, we expose an interface for discovering the memory locations of files for efficient RDMA access in CRUISE. The local agent can then communicate the memory locations to the remote agent. This method eliminates the additional memory copies and enables the remote agent to access the files without further interaction with the local agent.