
Scientific applications running on HPC systems share common I/O resources, including the PFS, and often suffer from inter-application I/O interference due to contention for shared storage resources. We explore mitigating this interference by coordinating I/O activities across applications. An example is scheduling applications such that the I/O cycle of one or a few applications overlaps with the compute cycles of others; thus, they will not access the PFS at the same time, reducing interference.
I/O Coordination
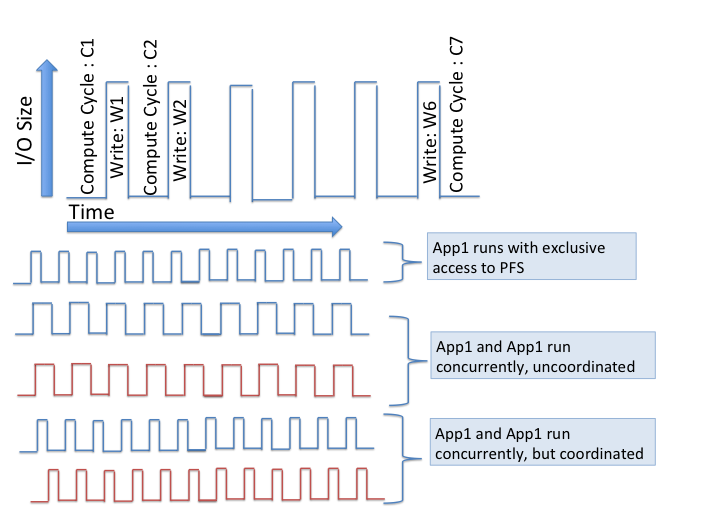
Scientific applications often have predictable I/O patterns for the majority of their executions, so we can leverage these patterns to enable I/O coordination between applications, as illustrated in the figure above. By overlapping compute and I/O cycles between App1 and App2, we can eliminate the I/O interference experienced by App1. App2 incurs a small overhead from the initial wait time needed to shift its phase such that App1 and App2 achieve the overlap.
I/O Coordination System
Our system model for achieving coordinated I/O scheduling between applications uses a global I/O scheduler and local I/O coordinator to manage application I/O requests and to co-schedule applications. The local coordinator takes control over application I/O requests by intercepting its I/O calls. Then it communicates with the global scheduler in order to obtain scheduling decisions and execute the I/O requests.
Application I/O Pattern Detection
Our framework for detecting execution patterns (compute and I/O cycles) of scientific applications collects and mines application I/O traces to understand I/O patterns. An I/O pattern can be extracted off-line or on-line while the application is running. We use detected execution patterns for achieving I/O coordination between applications.