
Disclaimer: This article is more than two years old. Developments in science and computing happen quickly, and more up-to-date resources on this topic may be available.
In This Issue:
- From the Director
- Lab Impact: Advancing LTT with a Multi-GPU Performance Boost and Machine Learning
- Collaborations: Highlighting Collaborations with Vendor Partners, and the Open Source Community
- Advancing the Discipline: Faster Fault Recovery for HPC Applications
- Path to Exascale: The Center for Efficient Exascale Discretizations (CEED) Co-design Center
- Highlights
From the CASC Director
October 1 marked the start of the new fiscal year and also the launch of many new LDRD (Laboratory Directed Research and Development) projects. Selection of the projects takes place over several months, beginning with an official call for proposals from the Laboratory Director in February. Depending on the funding category (Lab Wide, Feasibility Study, Exploratory Research, and Strategic Initiative), project ideas go through various stages of review, and final selections usually occur in late August or early September. The amount of effort that goes into writing, presenting, and reviewing the proposals reflects the abundance of research ideas that LLNL scientists generate and the relative scarcity of LDRD funds.
CASC has made a good showing in LDRD reviews over the years (see the Looking Back item, below). In fact, LDRD accounts for about 20% of CASC funding. This year, CASC scientists are leading two new projects:
- Terry Haut, "High-Order Finite Elements for Thermal Radiative Transfer on Curved Meshes"
- Chunhua Liao, "XPlacer: Extensible and Portable Optimizations of Data Placement in Memory"
In addition, CASC members will participate in several projects led by others. Congratulations to the teams that put together these new projects!
Sign up to be notified of future newsletters.
Contact: John May
Lab Impact | Advancing LTT with a Multi-GPU Performance Boost and Machine Learning
Livermore Tomography Tools (LTT) is a software package of tools to comprehensively process computed tomography (CT) data. It has been used in a variety of non-destructive evaluation (NDE) applications for material characterization, additive manufacturing (AM), weapon component imaging, and transportation security. Over the past year, CASC scientists collaborating with their Engineering counterparts have introduced cutting-edge multi-GPU techniques to increase the performance of LTT by several orders of magnitude.
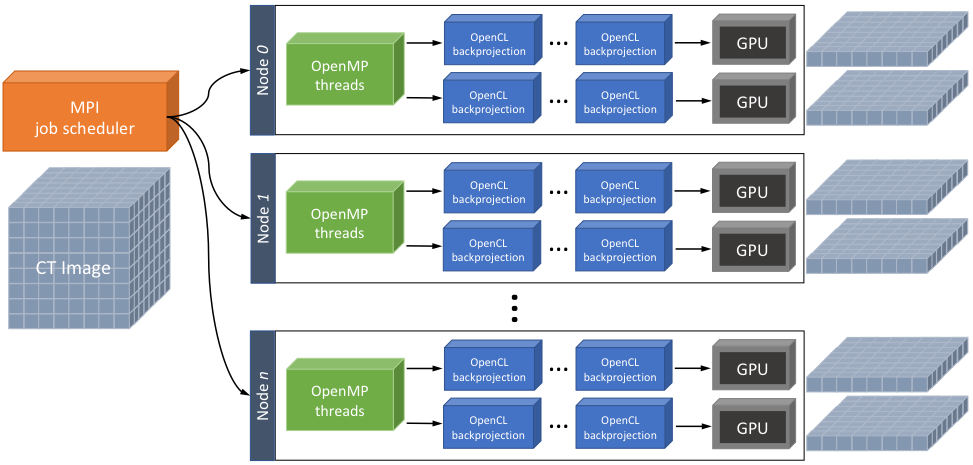
This dramatic performance improvement is essential due to increasing use of more challenging CT imaging with different modalities and materials as well as in various resolutions and sizes. One of the largest high-end NDE systems implemented by LLNL, called the Confined Large Optical Scintillator Screen and Imaging System (CoLOSSIS), generates 1,800 4K x 4K projections (115 GB) and a reconstructed 4K3 volume (256 GB). These high-resolution images make more accurate iterative reconstructions essentially impractical. For instance, single filtered back projection (FBP) of a 4K3 volume would usually take hours or even days using single GPU or CPU-based solutions. We can now perform those calculations in 1–3 minutes using our new methods utilizing 64 GPUs in parallel.
To boost the reconstruction capability and performance of LTT, the team has increasingly leveraged the power of GPU computing and high performance computing (HPC) clusters available in Livermore Computing (LC) after an initial single GPU prototype was developed. The resulting parallel, distributed reconstruction framework named LTT Cluster (LTTC) is a hybrid, two-tier implementation built on top of OpenCL, OpenMP, and MPI. The first tier is the core LTT combining OpenCL and OpenMP models to support multi-GPU parallel reconstruction in each compute node. GPU jobs in the core LTT are dynamically assigned to idle GPUs, enabling optimal load balancing. The second tier is the MPI-based job scheduler that distributes multiple LTT processes in parallel across nodes. The MPI scheduler instantiates multiple LTT processes based on the number of available GPU nodes, subdivides the entire job into pieces, and performs multiple LTT processes in parallel. The extensive experiments on LC's Surface system showed that multi-GPU LTTC significantly improves performance while retaining the reconstruction quality, compared to single GPU LTT and other existing solutions. The overall speedup of 64-GPU LTTC versus the single GPU LTT for 2K3 volume reconstruction is 38x–48x, and it is roughly 1,000 times faster than existing CPU solutions. This performance boost with Livermore GPU clusters will make a significant leap in many NDE and surveillance applications including CoLOSSIS.
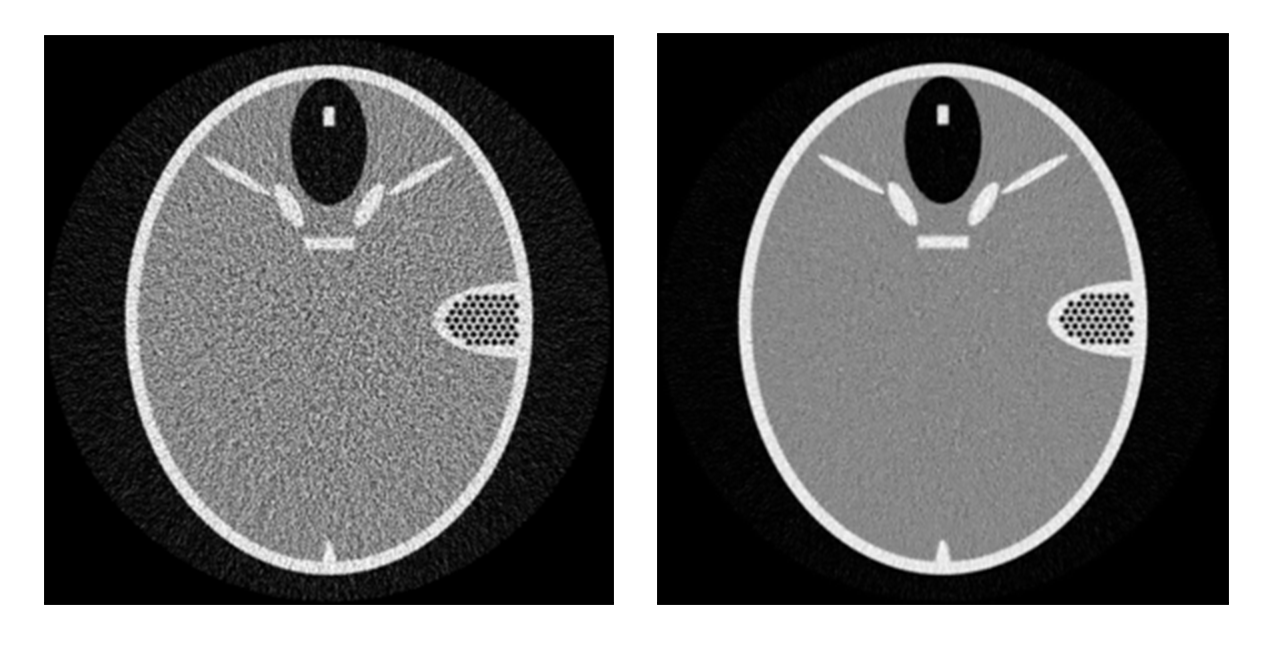
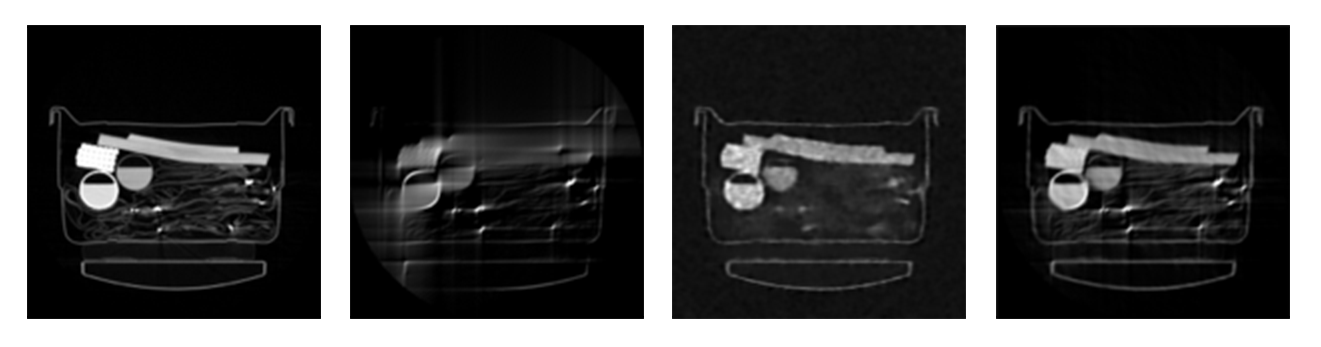
In addition to the dramatic speedup, the team is currently working on coupling machine learning techniques with LTT in order to advance the reconstruction quality. The team implemented an optimization-based iterative CT reconstruction algorithm with images derived from an over-complete dictionary of image patches. The noise suppression capability of this algorithm is shown in Fig 2. Another focus is on deep learning-aided reconstruction for ill-conditioned CT. In particular, the team is developing a baseline system in python that integrates the LTT-python framework into existing deep learning packages such as TensorFlow. It will allow us to train neural networks and to apply the output derived by the networks into LTT. The toy example, as shown in Figure 3, demonstrated that deep learning derived reconstruction can be effective in limited-angle CT applications.
Contact: Hyojin Kim
Collaborations | Highlighting Collaborations with Vendor Partners, and the Open Source Community
In this issue, we're highlighting several CASC collaborations which have recently been written about elsewhere, but which you may not have seen.
In our first highlighted article, CASC's Distinguished Member of Technical Staff Maya Gokhale and CASC post-doc Keita Iwabuchi worked closely with a CASC summer student Joshua Landgraf from the University of Texas at Austin, Livermore Computing staff, and Intel Corporation to evaluate a new memory technology under development at Intel called Optane 3D Xpoint ("cross point"). Intel provided the new hardware which was temporarily integrated into LC systems for the study. Software tools and benchmarks developed here in CASC were then used to do a detailed analysis.
Our next highlighted article will acquaint you with the Spack package manager. The brainchild of CASC's Todd Gamblin, Spack was borne out of the frustration of building and maintaining software on HPC systems. Unlike many computing platforms people use at home or on their desktop, HPC platforms and software development are characterized by customized environments, and the need to build and support multiple different configurations of software—a problem Spack addresses head on. The need for this solution is not unique to Todd, CASC, or LLNL, as Spack has quickly burgeoned into a flourishing open source project with a growing worldwide set of contributors you can read more about here: Spack: A Flexible Package Manager for HPC Software
Also, to hear (or read a transcript of) an interview with Todd about Spack, and life at LLNL as a computer scientist, check out this recent podcast.
Advancing the Discipline | Faster Fault Recovery for HPC Applications
Fail-stop failures may be more prevalent in future HPC systems as component count continues to increase and component reliability decreases. Although process and node failures are common in today’s systems, there is little a program can do to tolerate these failures. Most HPC applications use the Message-Passing Interface (MPI) for data communication. However, the MPI Standard does not currently support fault-tolerance, so if a process fails, the program automatically aborts. Large-scale HPC codes traditionally use checkpoint/restart to survive failures yet more efficient methods to tolerate failures could be used.
We studied the pros and cons of different fault-tolerance programming models for MPI applications. The models that we considered are: (a) returned error code checking, where if an error is returned in an MPI operation, recovery takes place; (b) try/catch blocks, where groups of MPI operations are protected, and (c) global restart, where the state of MPI is globally cleaned up and reinitialized upon a failure. When we weighted the programming complexity of using these models in large codes, their feasibility of implementation, and their performance, we found that global restart is the best option for large-scale bulk synchronous codes as it resembles the fault-tolerance semantics of checkpoint/restart, the most common fault-tolerance approach in HPC.
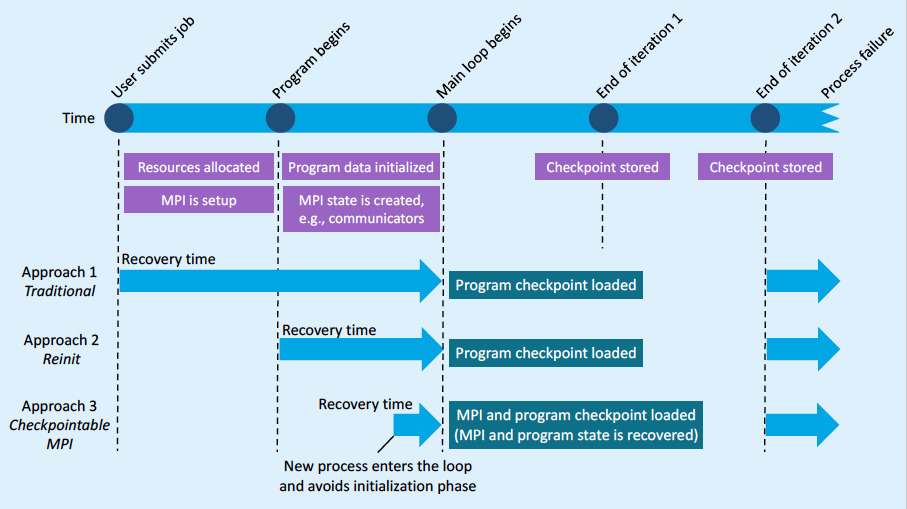
The Figure below illustrates different approaches to realize the global restart model.
Traditional checkpoint/restart (approach 1) is the simplest one. Here, the program saves a checkpoint of the application state periodically in the application main loop. When a process failure occurs, the job is killed and resubmitted by the user; the program then loads the most recent checkpoint and continues.
A more efficient approach is Reinit (approach 2), in which MPI is automatically reinitialized when a failure is detected. In this approach, new processes are used to replace failed processes, where new processes can be either spawned immediately after a failure or can be pre-allocated by the resource manager. Both mechanisms are expected to be widely supported in next-generation resource managers (see Flux). In this approach, all processes are restarted from the main function of the program; however, the job is not terminated, thus the time for resource allocation, process connections, and MPI setup is avoided. Although Reinit eliminates job startup time, the program still has to perform its initialization phase before reaching the main loop where the failure occurred—initialization commonly involves MPI state creation, e.g., creation of MPI communicators.
Approach 3, Checkpointable MPI, removes the requirement of processes re-executing the initialization phase. In this approach, checkpoints of the MPI state, along with the application state, are stored. This allows the new process to fix both application and MPI state faster than the previous approaches, virtually replacing the failed process with a fresh instance that can quickly continue from where the failed process died.
This work is supported by LDRD funding and by the Exascale Computing Project. The Reinit model is being discussed in the MPI forum to provide fault tolerance for large-scale bulk synchronous codes.
Contact: Ignacio Laguna
The Path to Exascale | The Center for Efficient Exascale Discretizations (CEED) Co-design Center
Fully exploiting future exascale architectures will require a rethinking of the algorithms used in the large-scale applications that advance many science areas vital to the DOE, such as global climate modeling, turbulent combustion in internal combustion engines, nuclear reactor modeling, additive manufacturing, subsurface flow, and other national security applications. The newly established Center for Efficient Exascale Discretizations (CEED) in the Exascale Computing Project (ECP) aims to help these DOE applications take full advantage of exascale hardware by using state-of-the-art efficient discretization algorithms that provide an order of magnitude performance improvement over traditional methods. CEED is one of five co-design centers established by the ECP, each of which targets different features and challenges relating to exascale computing.
Addressing the computational motif of spectral and high-order finite element methods, CEED is developing discretization libraries to enable unstructured applications based on partial differential equations to take full advantage of exascale resources without reinventing the wheel of complicated finite element machinery on coming exascale hardware. The focus is on high-order methods, as recent developments in supercomputing make it increasingly clear that these types of algorithms have the potential to achieve optimal performance and deliver fast, efficient, and accurate simulations on exascale systems. These architectures favor algorithms that expose ultra-fine-grain parallelism and maximize the ratio of floating-point operations to energy-intensive data movement, such as matrix-free partial assembly that exploits the tensor-product structure of the canonical mesh elements and finite element spaces.
CEED’s co-design approach is based on close collaboration between its Applications, Hardware, and Software thrusts, each of which has a two-way, push-and-pull relationship with the external application and hardware and software technologies teams. CEED’s Finite Elements thrust serves as a central hub that ties together, coordinates and contributes to the efforts in all thrusts. CEED scientists work closely with hardware vendors and algorithm and software developers, and collaborate with application scientists to meet their needs. For example, CEED is also developing a variety of benchmarks and miniapps (also referred to as CEEDlings) encapsulating key physics and numerical kernels of high-order applications. The miniapps are designed to be used in a variety of co-design activities with ECP vendors, software technologies projects, and external partners.
Some of the recent activities in the center include the development of Laghos, a new MFEM-based mini-app that for the first time captures the basic structure of high-order compressible shock hydrocodes, such as the BLAST code at LLNL; the proposal of the initial set of bake-off (benchmark) problems designed to test and compare the performance of high-order codes internally, and in the broader high-order community; as well as on-going research and development efforts in the areas of high-order meshing, unstructured AMR, efficient operator format, dense tensor contractions, scalable matrix-free solvers and visualization of high-order meshes and functions.
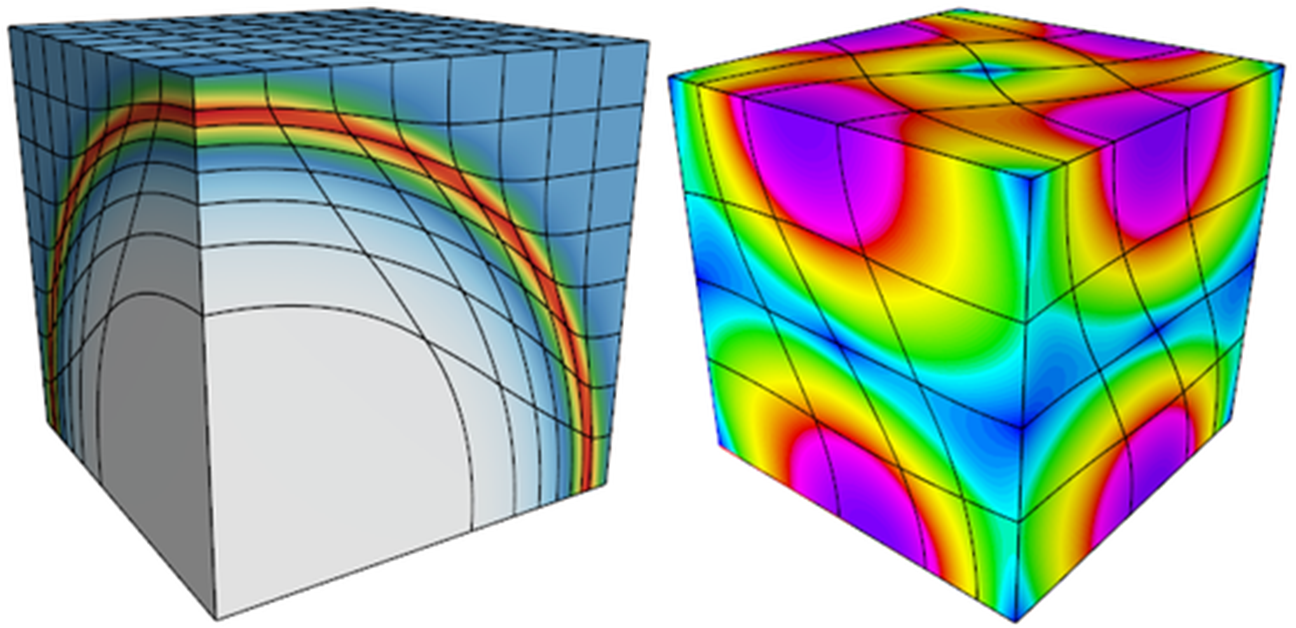
CEED is a research partnership of 30+ researchers from two DOE labs and five universities, including members of the MFEM, Nek5000, MAGMA, OCCA and PETSc projects. The center is led by LLNL working with Argonne National Laboratory; the University of Illinois Urbana-Champaign; Virginia Tech; the University of Tennessee, Knoxville; the University of Colorado, Boulder; and the Rensselaer Polytechnic Institute.

Contact: Tzanio Kolev or visit CEED's website.
CASC Highlights
New Hires (since July 1, 2017)
- Alyson Fox (University of Colorado)
- Jean-Sylvain Camier (CEA, France)
- Yohann Dudouit (CERFACS, France)
- Bryce Campbell (MIT)
- Craig Rasmussen (University of Oregon)
Awards
- Timothy La Fond, Geoffrey Sanders, Christine Klymko, and Van Henson coauthored a paper that won an Innovation Award in the IEEE/Amazon/DARPA Graph Challenge.
- Markus Schordan was Overall Winner in an automatic software verification challenge.
Looking back...
Two of CASC's earliest LDRD projects were led by its founder, Steve Ashby. The first of these got underway before the inception of CASC in 1996. It focused on modeling the flow of water underground, both for environmental remediation and for water resource management. The resulting software package was called ParFlow, and it was a mainstay of CASC research for many years. Today, ParFlow is an international open source project led by former LLNL employee Reed Maxwell at the Colorado School of Mines, and LLNL still contributes to it.
Ashby's second LDRD project, begun at the end of 1996, developed two important technologies for HPC, multigrid-based linear solvers and structured adaptive mesh refinement. The multigrid research produced the hypre library, which is still an important project in CASC and a key technology for several LLNL programs. The structured AMR research led to the SAMRAI library, which also plays an important role in LLNL codes today. In an article for the 1997 LDRD Annual Report, Ashby pointed out that SAMRAI could run on a wide range of parallel computers, including the IBM SP2, the SGI Origin 2000, and the Cray T3E.
Newsletter Sign-up
Sign up to be notified of future newsletters.