
Jump to: Research | Get in Touch
High performance computing (HPC) systems have become more powerful by using more components. As the system mean time before failure correspondingly drops, applications must checkpoint frequently to make progress. However, the costs in time and bandwidth of checkpointing to a parallel file system (PFS) become prohibitive at large scales. A solution to this problem is multilevel checkpointing.
Multilevel checkpointing allows applications to take both frequent, inexpensive checkpoints and less frequent, more resilient checkpoints, resulting in better efficiency and reduced load on the PFS. The slowest but most resilient level writes to the PFS, which can withstand an entire system failure
Faster checkpointing for the most common failure modes uses node-local storage (e.g., random-access memory [RAM], Flash, disk) and applies cross-node redundancy schemes. Most failures only disable one or two nodes, and multinode failures often disable nodes in a predictable pattern. Thus, an application can usually recover from a less resilient checkpoint level, given well-chosen redundancy schemes.
To evaluate this approach in a large-scale production system context, LLNL researchers developed the Scalable Checkpoint/Restart (SCR) library. SCR has been used in production since 2007 using RAM disks and solid-state drives on Linux clusters. Overall, with SCR, HPC jobs run more efficiently, recover more work upon failure, and reduce load on critical shared resources such as the PFS and the network infrastructure.
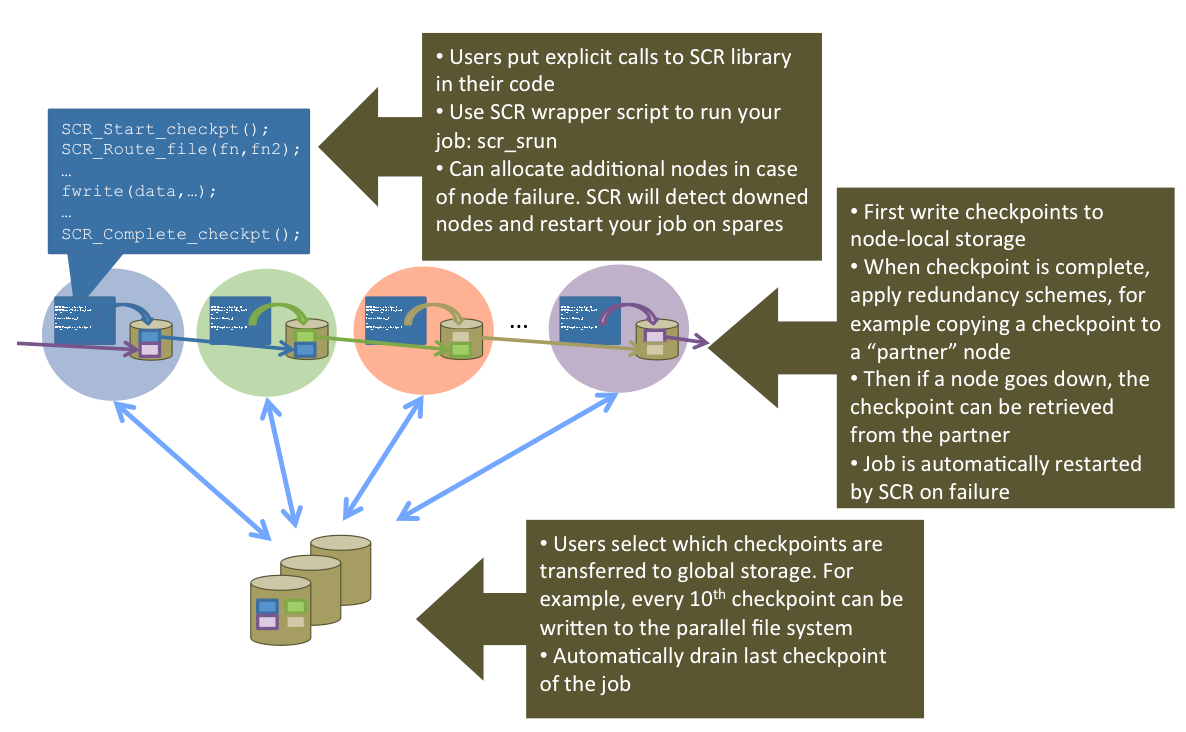
The SCR framework has been successful at reducing overhead on modern HPC systems, and evolving these methods is critical in the extreme-scale computing era. Our research efforts have reduced the checkpointing overhead even further by exploring strategies such as a fast, node-local file system written especially for checkpoint input/output (I/O), checkpoint compression, asynchronous checkpoint movement, and managing the use of hierarchical storage (e.g., using burst buffers as an intermediate step before reaching the PFS).
Research
The SCR team conducts research in HPC application checkpointing that can be broadly classified into the following categories.
- Multilevel Checkpointing: Multilevel checkpointing greatly reduces checkpointing overhead and can bridge the gap for checkpoint-restart in the exascale computing era. SCR is an example of a multilevel checkpointing system.
- File System Strategies: Application checkpoints are typically stored on external PFSs, but limited bandwidth makes this a time-consuming operation. Multilevel checkpointing systems like SCR alleviate this bottleneck by caching checkpoints in storage located close to the compute nodes.
- Checkpoint Compression: As applications scale up, checkpoint-restart incurs high overheads due to contention for overloaded PFS resources, forcing large-scale applications to reduce checkpoint frequency and, thus, lose compute time in the event of failure. Our compression research explores aggregating and compressing checkpoints based on data semantics in order to reduce contention for shared PFS resources and ultimately make checkpoint-restart affordable for HPC applications.
- Asynchronous Checkpointing: Our asynchronous checkpointing system writes checkpoints through agents running on additional nodes that asynchronously transfer checkpoints from compute nodes to a PFS. The approach has two key advantages: (1) It lowers application checkpoint overhead by overlapping computation and writing checkpoints to the PFS, and (2) it reduces PFS load by using fewer concurrent writers and moderating the rate of PFS I/O operations.
- I/O Scheduling: Scientific applications running on HPC systems can suffer from I/O bottlenecks during I/O-intensive operations such as checkpointing. Moreover, as multiple jobs share common I/O resources, including the PFS, they often suffer from inter-application I/O interference. In this research, we explore these issues in present and future HPC storage systems using I/O scheduling techniques.
Get in Touch
The quickest way to post bugs or ask questions is to submit an issue on our GitHub repository.